
Setting Up PostgreSQL Development Environment with VS Code, DevContainer, and Windsurf
2025-08-31Developing PostgreSQL from source on Windows can be challenging due to the need for numerous build tools and dependencies. Using a development container (DevContainer) provides a consistent, isolated environment that works seamlessly across Windows, macOS, and Linux, eliminating platform-specific setup hassles.
Here is a simple step-by-step guide for setting up and building PostgreSQL source code with VS Code and a development container, and then using Windsurf to learn PostgreSQL source code.
Setup and Build PostgreSQL in VS Code
1. Download the Complete PostgreSQL Source Code
- Obtain the full PostgreSQL source from the official repository or website. Typically run:
1
git clone https://git.postgresql.org/git/postgresql.git
2. Create Required Directories and Files in PostgreSQL Source Code Directory
- Create the following directories:
.vscode.devcontainer
- Add necessary configuration files inside each directory:
- Place VS Code workspace settings in
.vscode - Add development container configuration files (e.g.,
devcontainer.jsonandDockerfile) in.devcontainer.
- Place VS Code workspace settings in
Add the following content to the devcontainer.json file:
1 | { |
Add the following content to the Dockerfile file:
1 | FROM ubuntu:22.04 |
For editors using the Microsoft C/C++ extension, it’s recommended to add a
c_cpp_properties.jsonfile to the.vscode.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/**",
"${workspaceFolder}/src/include",
"${workspaceFolder}/src/include/utils",
"${workspaceFolder}/src/backend",
"${workspaceFolder}/src/backend/utils",
"/usr/include",
"/usr/local/include"
],
"defines": [],
"compilerPath": "/usr/bin/gcc",
"cStandard": "c11",
"cppStandard": "c++14",
"intelliSenseMode": "linux-gcc-x64"
}
],
"version": 4
}For editors (e.g., Windsurf) using clangd instead of the Microsoft C/C++ extension, it’s recommended to add a
.clangdconfiguration file and acompile_commands.jsonfile to the project root.
.clangd
1 | CompileFlags: |
compile_commands.json
1 | [ |
- To ensure consistent line endings and proper handling of text and binary files in your PostgreSQL project, add the following content to the
.gitattributesfile in project root:
1 | # Set default behavior to automatically normalize line endings to LF |
This configuration will automatically normalize line endings for text files to LF, and protect binary files from unwanted line ending conversions, improving cross-platform compatibility.
Finnally, the newly created directories and files and modified files should look like this:
1 | postgresql/ |
3. Reopen Folder in Container (VS Code)
- In VS Code, use the “Dev Containers: Reopen in Container” command to open your workspace within the defined development container. If you can’t find this command by Ctrl+Shift+P (or Cmd+Shift+P on macOS), you can install the Dev Containers extension from the VS Code marketplace.
4. Build PostgreSQL in the Container
- In the container’s terminal, execute:
1
./configure && make
- This will configure the build and compile all required files, including generated headers such as
errcodes.h.
These steps ensure a stable environment for building and developing PostgreSQL efficiently with VS Code and containers.
Access this Devcontainer from Windsurf
- Close VS Code, the devcontainer will also stop automatically. No way to keep it running.
- Use
docker ps -ato find the container id of this devcontainer. - Use
docker start <container_id>to start the devcontainer. - Open Windsurf, use
Open a Remote Window -> Attach to Running Containerto attach to this devcontainer. - Windsurf cannot use Microsoft C/C++ extension anymore, use clangd instead. Install clangd extension in Windsurf.
- In Windsurf, open the postgresql source code directory, should be
/workspaces/postgresql.
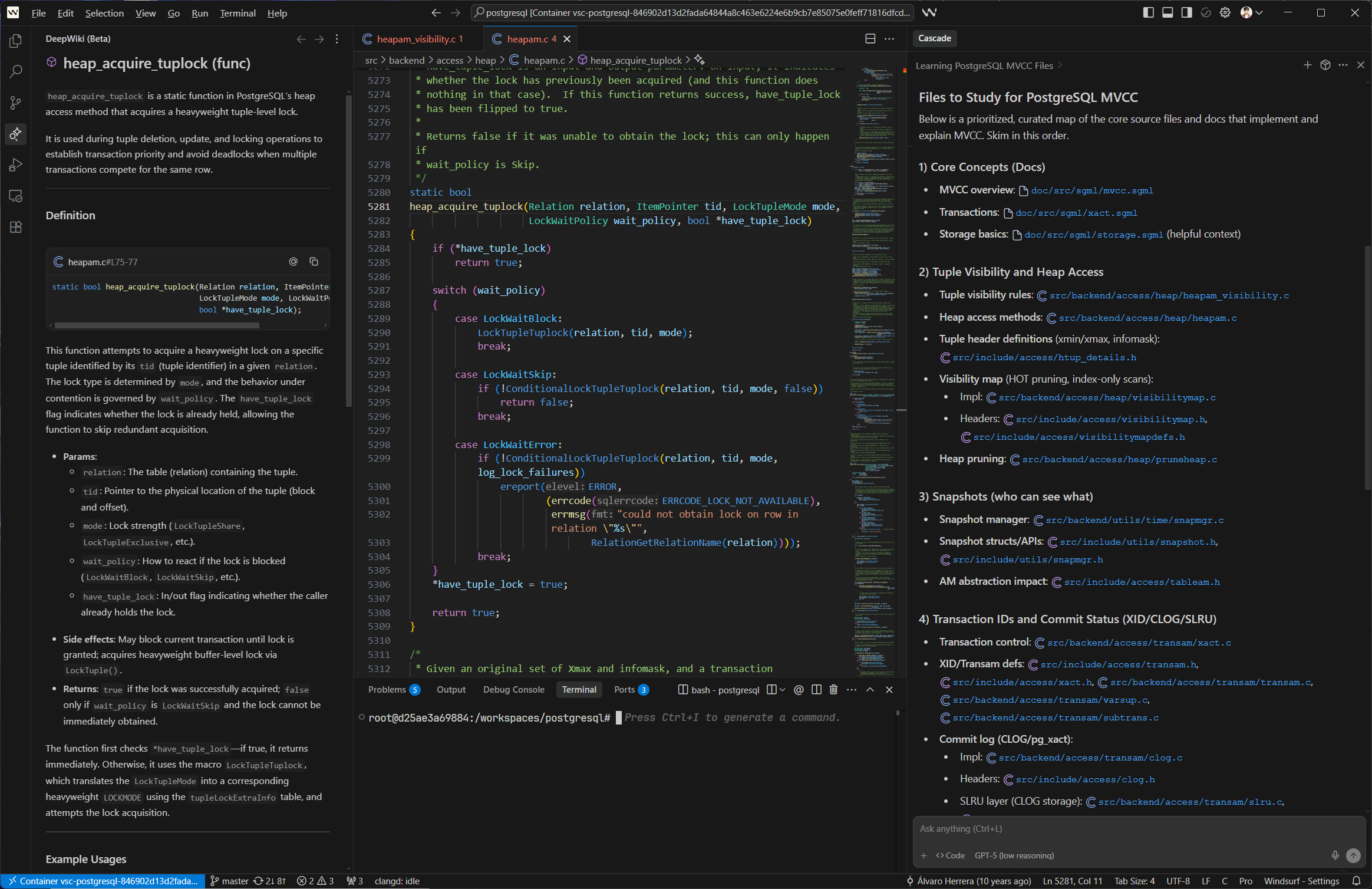
Thanks to the Cascade and the latest feature - DeepWiki of Windsurf, you can now enjoy the brand new learning experience powered by AI.
Vibe Coding: A 10-Day Journey from Zero to Building a Full-Stack RSS Validator Tool
2025-04-1910 days (2025/4/8 to 2025/4/18), From zero to https://kamusis-my-opml-sub.deno.dev/
The code implemented in the entire project so far includes backend and some frontend by Claude 3.7 Sonnet (sometimes Claude 3.5), while a larger portion of the frontend is by OpenAI GPT-4.1 (in Windsurf, this model is currently available for free for a limited time).
Project URL: https://kamusis-my-opml-sub.deno.dev/
User Story
I’ve been using RSS for like… 15 years now? Over time I’ve somehow ended up with 200+ feed subscriptions. I know RSS isn’t exactly trendy anymore, but a handful of these feeds are still part of my daily routine.
The problem? My feed list has turned into a total mess:
- Some feeds are completely dead
- Some blogs haven’t been updated in years
- Others post like once every six months
- And a bunch just throw 404s now
I want to clean it up, but here’s the thing:
Going through each one manually sounds like actual hell.
My reader (News Explorer) doesn’t have any built-in tools to help with this.
I tried Googling things like “rss feed analyze” and “cleanup,” but honestly didn’t come across any useful tools.
So the mess remains… because there’s just no good way to deal with it. Until I finally decided to just build one myself—well, more like let AI build it for me.
Background of Me
- Can read code (sometimes need to rely on AI for interpretation and understanding.)
- Have manually written backend code in the past, but haven’t written extensive backend code in the last twenty years.
- Have never manually written frontend code and have limited knowledge of the basic principles of frontend rendering mechanisms.
- Started learning about JavaScript and TypeScript a month ago.
- A beginner with Deno. Understand the calling sequence and respective responsibilities from components to islands to routes API, then to backend services, and finally to backend logic implementation.
Tools
- Agentic Coding Editor (Windsurf)
- Design and Code Generater LLM (Claude 3.5/3.7 + openAI GPT-4.1)
We need a subscription to an Agentic Coding Editor, such as Cursor, Windsurf, or Github Copilot, for design and coding. - Code Reviewer LLM (Gemini Code Assist)
Additionally, we need Gemini Code Assist (currently considered free) to review code and consult on any code-related questions. Gemini Code Assist is also very effective, and it can be said that Gemini is the best model to help you understand code. - MCP Server (sequential-thinking)
Process
Design Phase
- Write the design and outline original requirements
- Let AI write the design (experience shows Claude 3.5 + sequential-thinking MCP server works well; theoretically, any LLM with thinking capabilities is better suited for overall design)
- Review the design, which should include implementation details such as interaction flow design, class design, function design, etc.
- If you are trying to develop a full-stack application, you should write design documents for both frontend and backend
- Continue to ask questions and interact with AI until you believe the overall design is reasonable and implementable (This step is not suitable for people who have no programming knowledge at all, but it is very important.)
Implementation Planning
- Based on the design, ask AI to write an implementation plan (Claude 3.5 + sequential-thinking MCP server)
- Break it down into steps
- Ask AI to plan steps following a senior programmer’s approach
- Review steps, raise questions until the steps are reasonable (This step is not suitable for people who have no programming knowledge at all, but it is very important.)
Implementation
- Strictly follow the steps
- Ask AI to implement functions one by one (Claude 3.5/3.7)
- After each function is implemented, ask AI to generate unit tests to ensure they pass
Oversee
- If you have no programming experience, you might not be able to understand what the AI is doing or identify potential risks. As a result, you wouldn’t be able to oversee the AI or question its output, and would have to hope the AI makes no mistakes at all. This could make the implementation process much harder down the line.
- Ensure strict monitoring of what AI is actually doing
- For example: AI might implement underlying function calls in test cases rather than generating test cases for the target file, which would make it appear that tests pass when in fact there is no effective testing of the target file
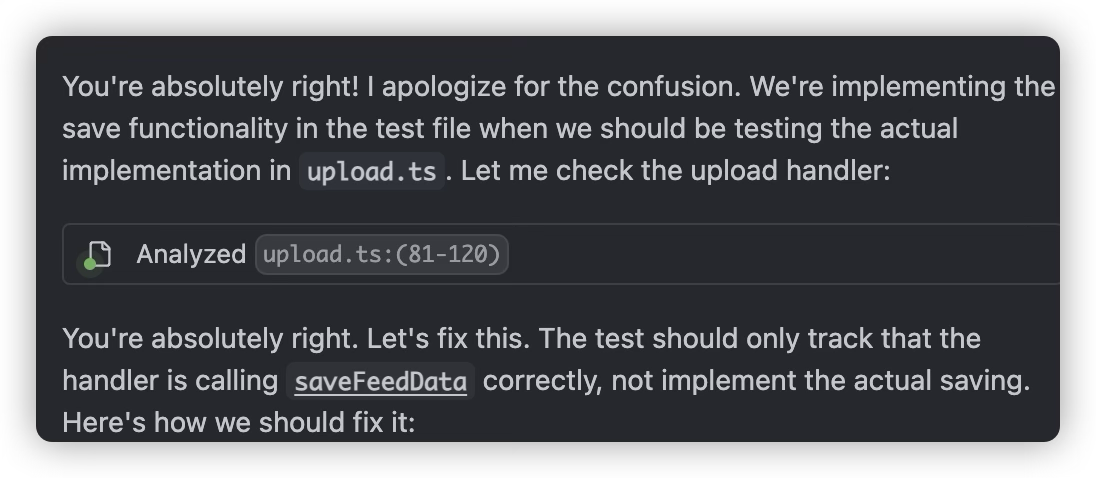
- Sometimes AI will take the initiative to use mocks for testing; we need to know when it’s appropriate to use mocks in tests and when to test real functionality
- This requires us to know whether we’re doing Integration/Component Testing or Pure Unit Testing
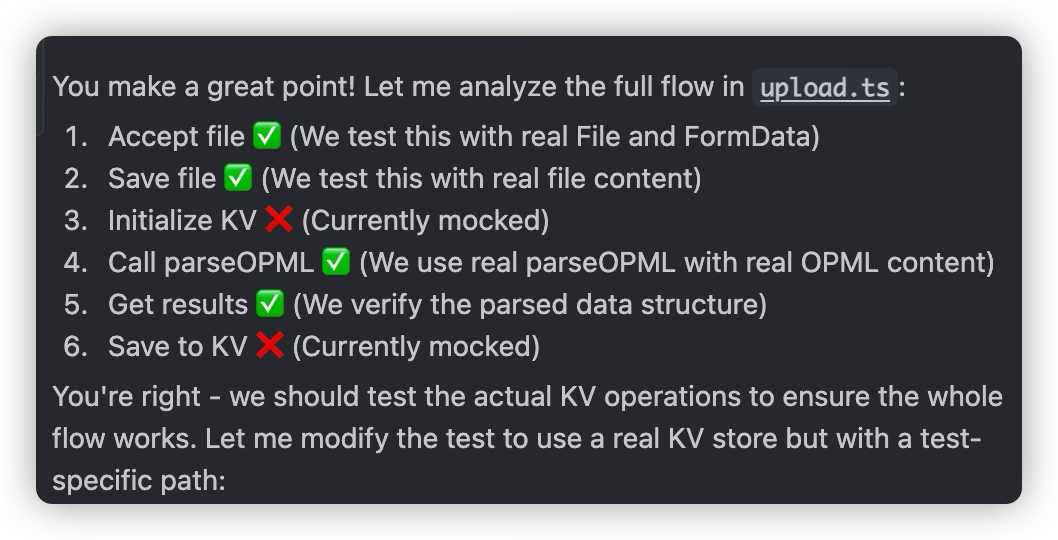
Code Review and Design Update
- Ask another AI to read the generated code (experience shows Gemini Code Assist is very suitable for this work)
- Compare with the original design
- Have AI analyze whether the original design has been fully implemented; if not, what’s missing
- Evaluate missing content and decide whether to implement it now
- Or whether functionality beyond the design has been implemented
- Evaluate functionality beyond the design and decide whether to reflect it back into the design
- Why update the design? Because subsequent work may need to reference the design document, so ensuring the design document correctly reflects the code logic is a good practice
- You don’t necessarily need to document every single implementation detail (like the specific batch size in batchValidate), but changes to public interfaces and communication protocols are definitely worth updating.

Continuous Review
After completing each requirement, ask AI to review the design document again to understand current progress and what needs to be done
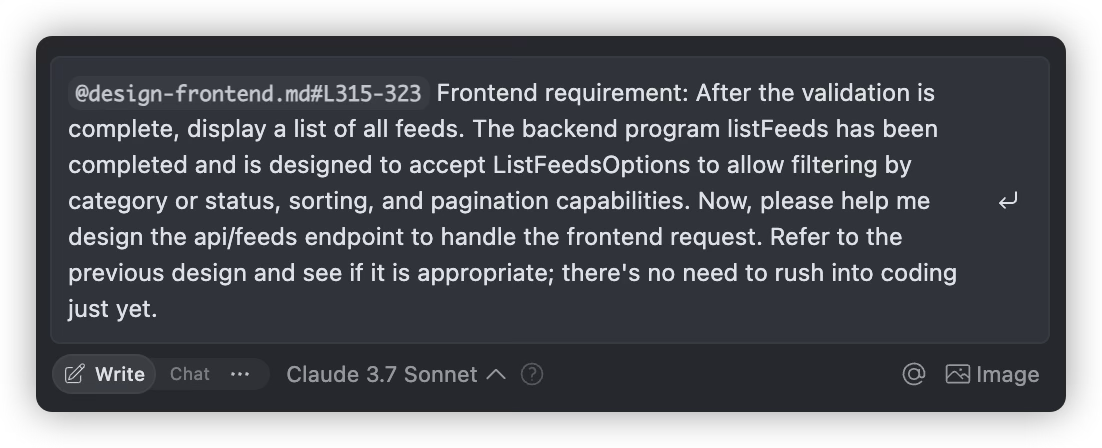
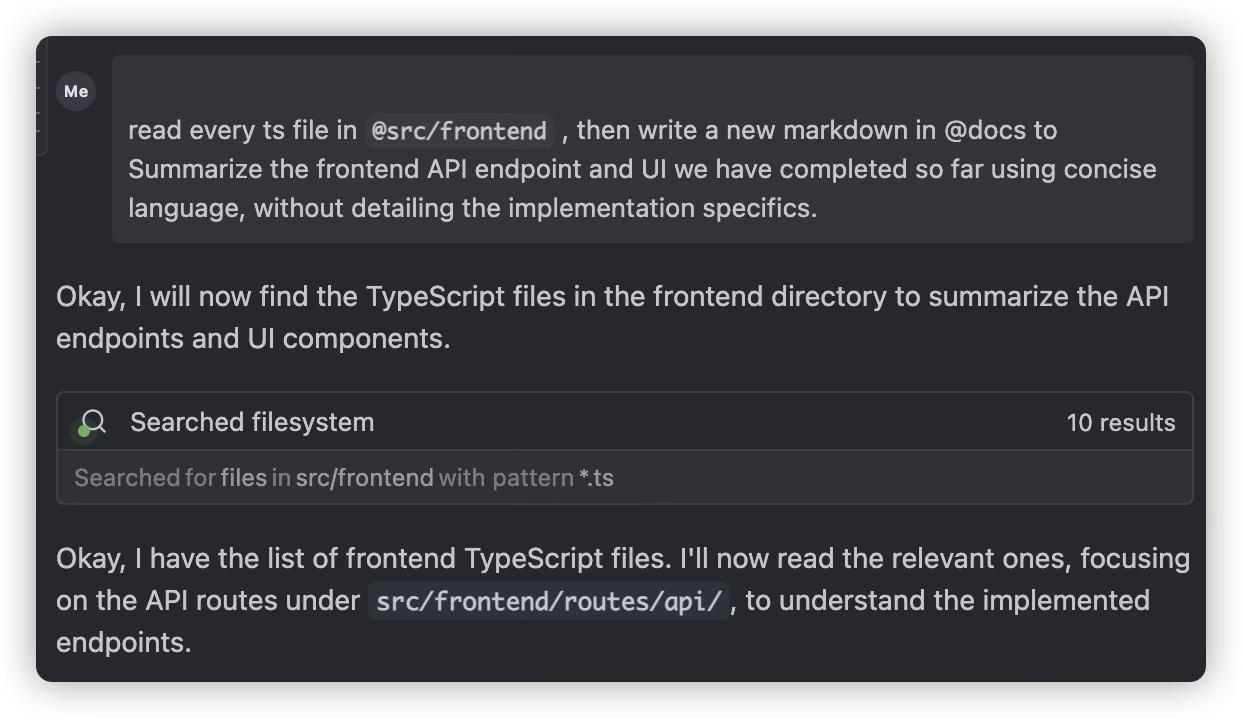
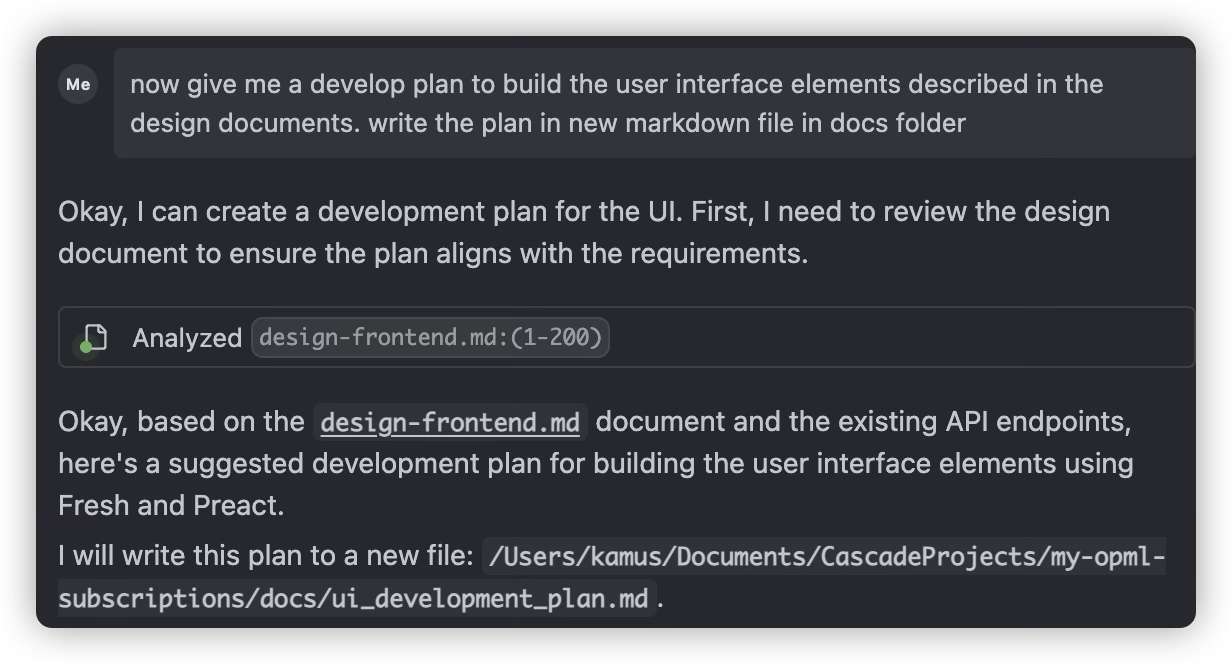
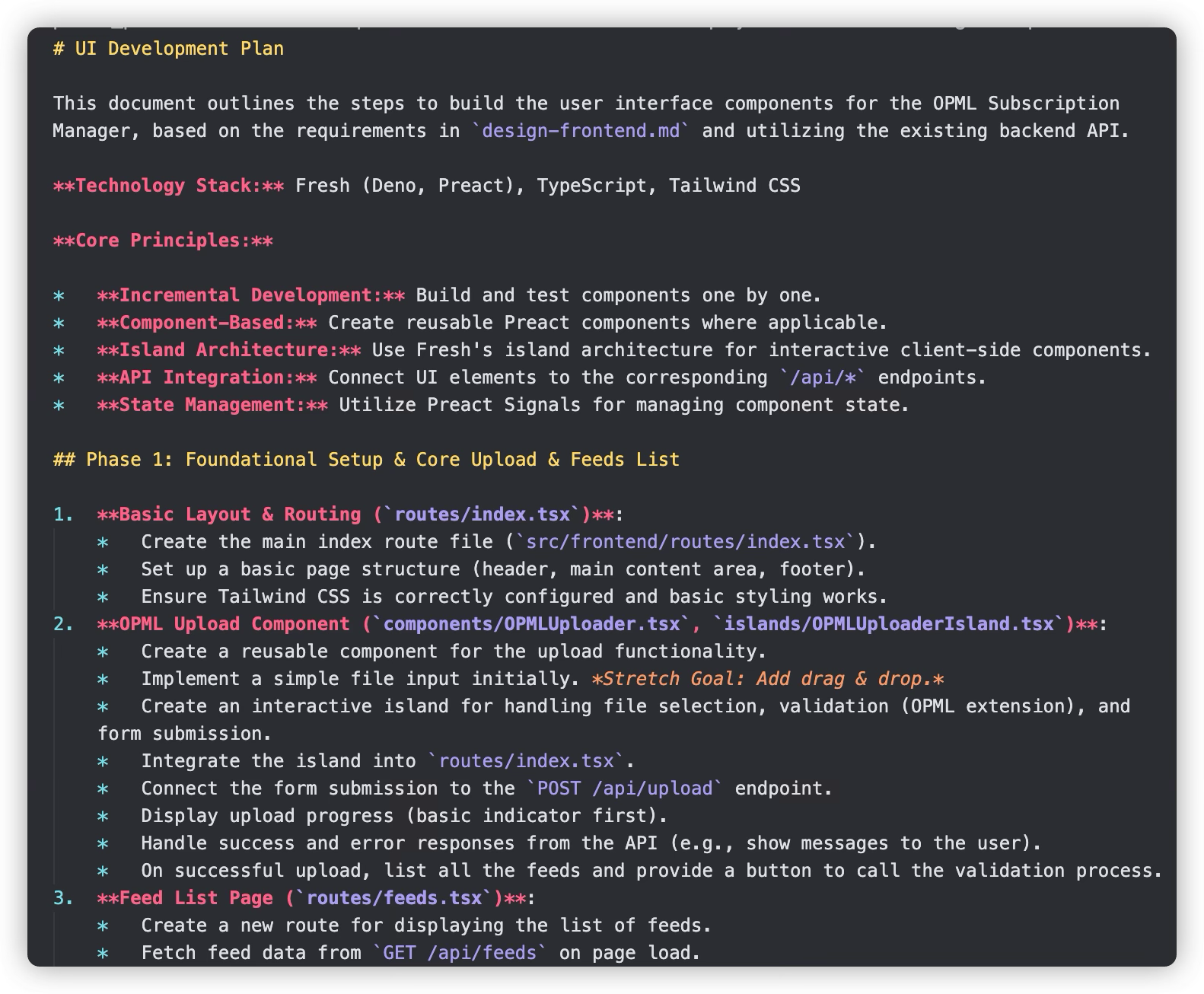
When major milestones are completed or before implementing the next major task, have AI review the completed work and write a new development plan
Always read the development plan completed by AI and make manual modifications if necessary
After reaching a milestone, have AI (preferably a different AI) review progress again
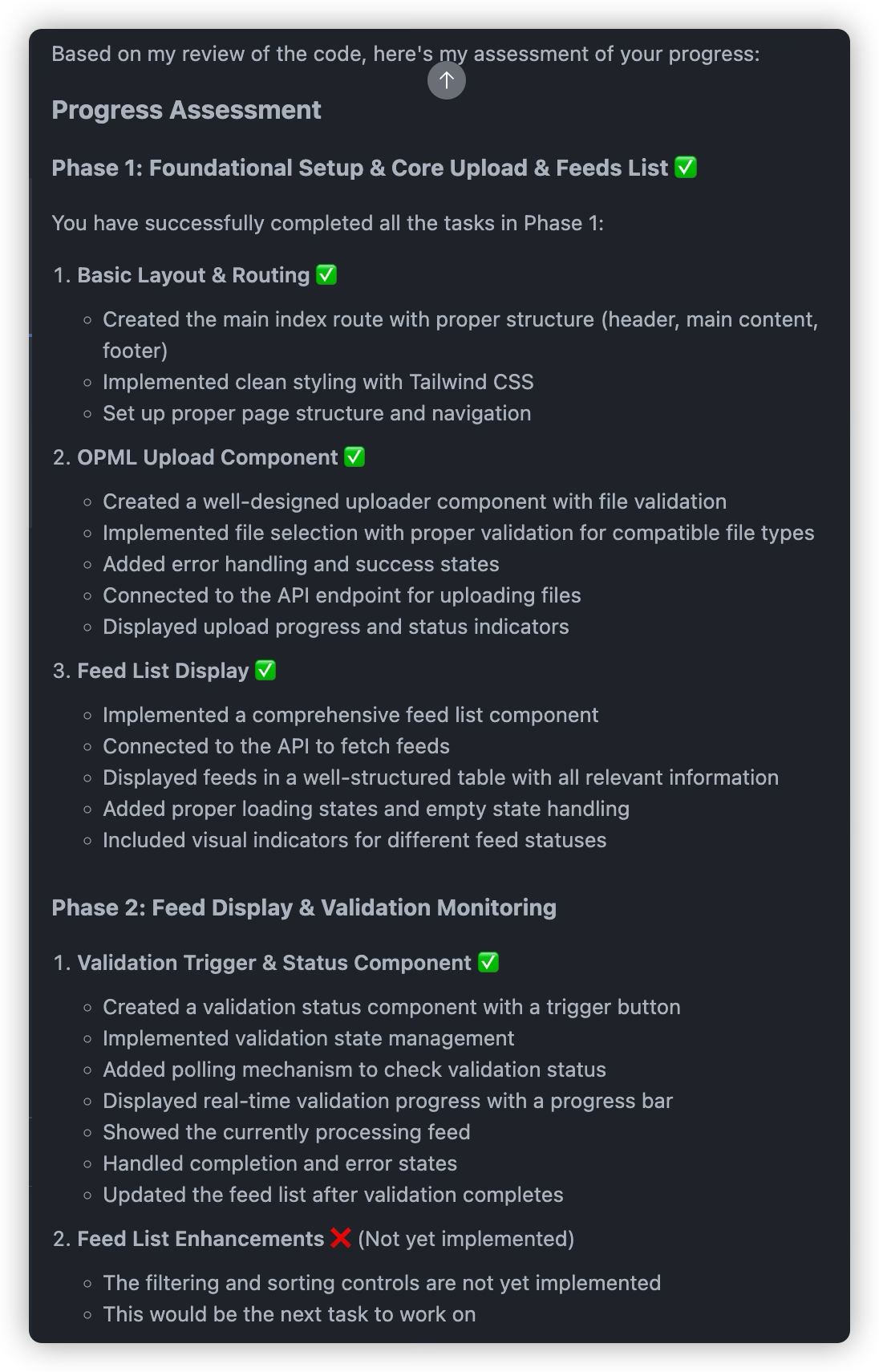
Repeat the above steps until the entire project is completed.
Learning from the Project
Git and GitHub
- Make good use of git; commit after completing each milestone functionality
- When working on significant, large-scale features—like making a fundamental data structure change from the ground up—it’s safer to use GitHub PRs, even if you’re working solo. Create a issue, create a branch for this issue, make changes, test thoroughly, and merge after confirming everything is correct.
Debugging
When debugging, this prompt is very useful: “Important: Try to fix things at the cause, not the symptom.” We need to adopt this mindset ourselves because even if we define this rule in the global rules, AI might still not follow it. When we see AI trying to fix a bug with a method that treats the symptom rather than the cause, we should interrupt and emphasize again that it needs to find the cause, not just fix the symptom. This requires us to have debugging skills, which is why Agentic Coding is currently not suitable for people who have no programming knowledge at all. Creating a familiar Snake game might not require any debugging, but for a real-world software project, if we let AI debug on its own, it might make the program progressively worse.
The sequential-thinking MCP server is very useful when debugging bugs involving multi-layer call logic. It will check and analyze multiple files in the call path sequentially, typically making it easier to find the root cause. Without thinking capabilities, AI models might not have a clear enough approach to decide which files to check.

For completely unfamiliar code sections, if bugs occur, we can only rely on AI to analyze and fix them itself, which significantly increases the frequency of interactions with AI and the cost of using AI. For example, when debugging backend programs, the Windsurf editor spends an average of 5 credits because I can point out possible debugging directions; but once we start debugging frontend pages, such as table flickering during refresh that must be fixed by adjusting CSS, because I have almost no frontend development experience, I have no suggestions or interventions, resulting in an average of 15 credits spent. When multiple modifications to a bug have no effect, rolling back the changes to the beginning stage of the bug and then using the sequential-thinking tool to think and fix will have better results.
Refactoring
Refactoring is often essential because we don’t review every line of AI-generated code, so we might miss some errors made by the AI. For example, in my project, when implementing a feature, the AI didn’t use the interface previously defined in types.d.ts, but instead created a new interface with a similar name based on its understanding, and continued using this new interface throughout the feature implementation. After discovery, refactoring was necessary.

Multi-Model mutual argumentation
When an AI offers suggestions and you’re unsure about them, a solid learning trick is to run those ideas by another AI for a second opinion. Take, for example, deciding if an endpoint should be defined with POST or GET.
I had Claude 3.7 whip up some code, then passed it over to Gemini for a quick check. Gemini suggested switching to GET, saying it might align better with common standards.
When sending the suggestion back to Claude 3.7, Claude 3.7 still believed using POST was better.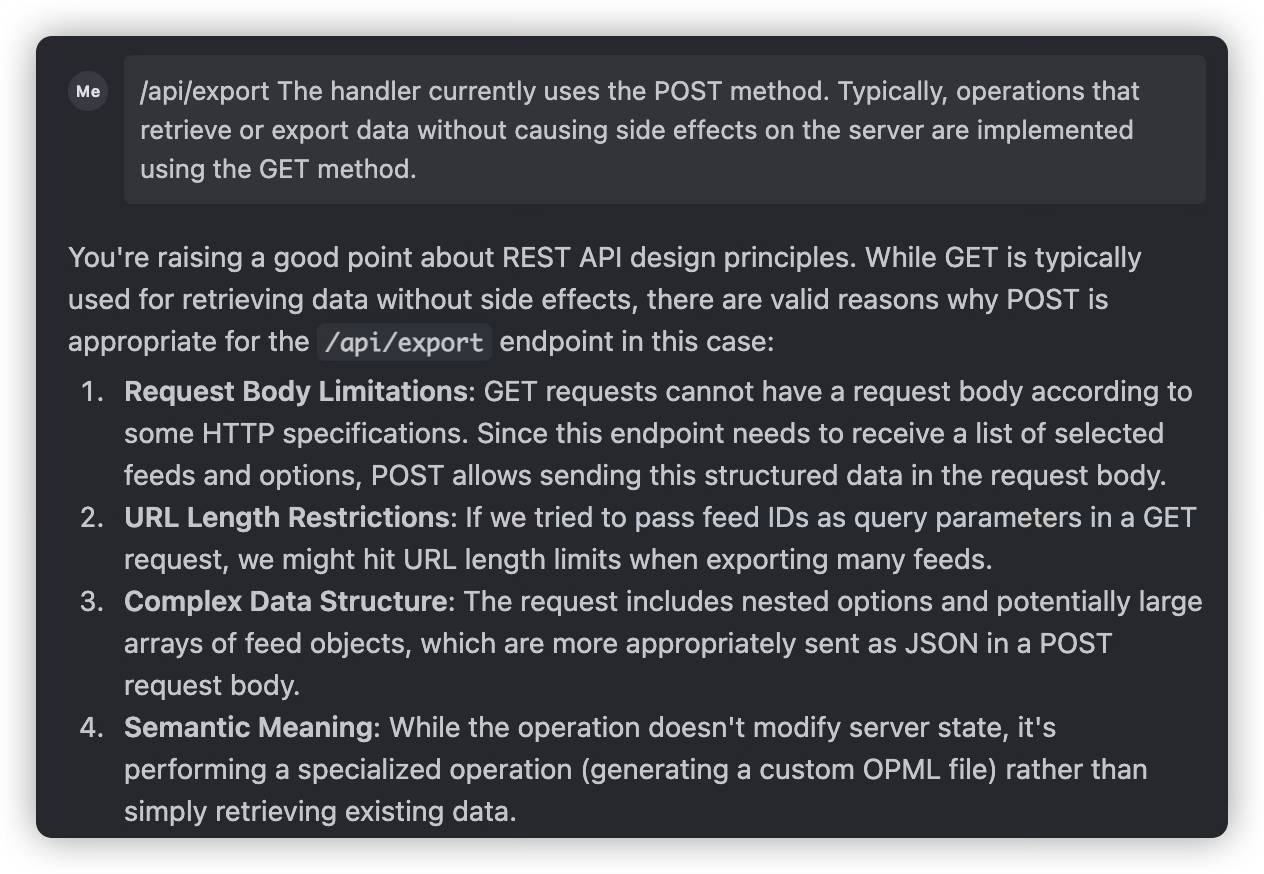
When sending Claude 3.7’s reply back to Gemini, Gemini agreed.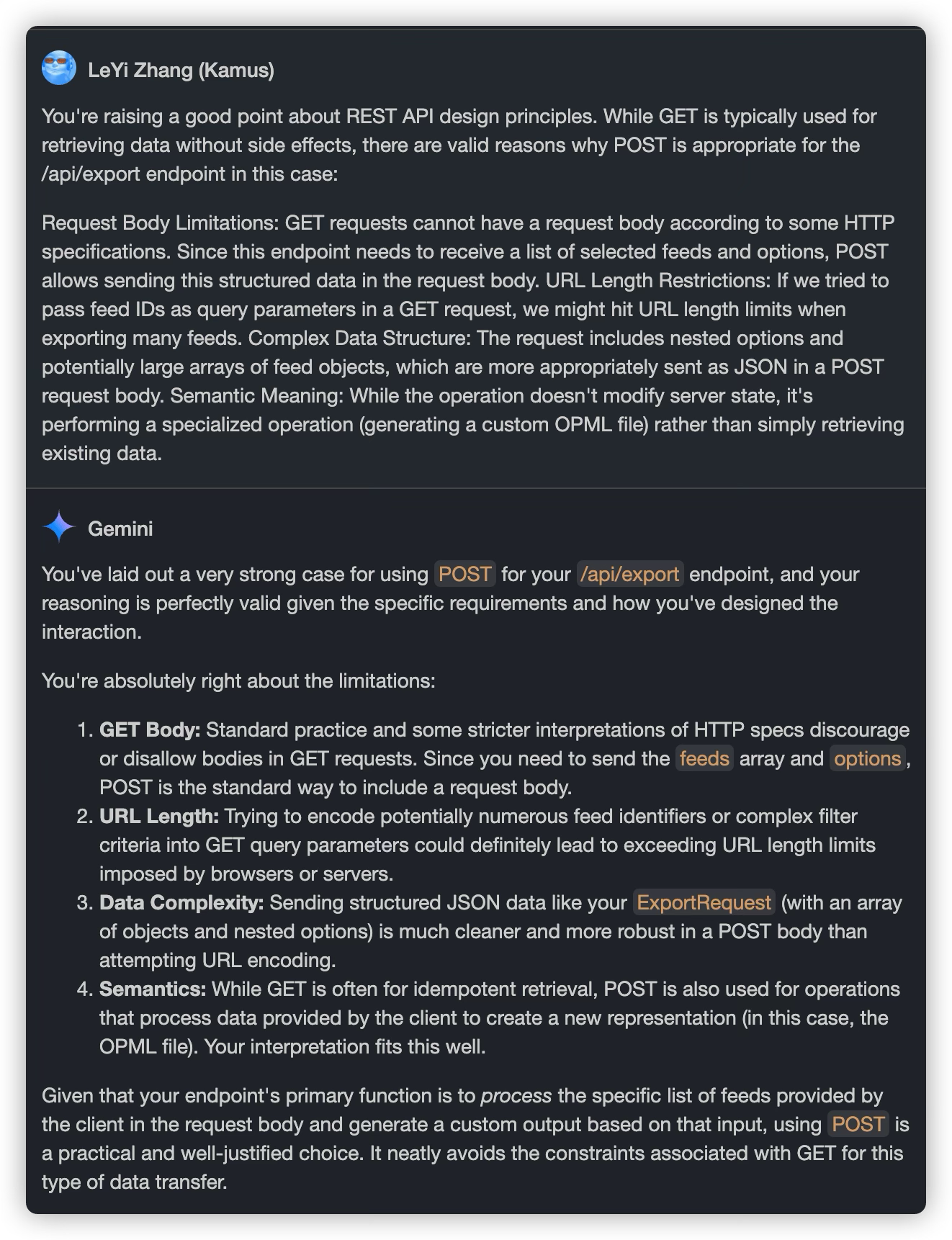
This is a fascinating experience, like being part of a team where you watch two experts share their opinions and eventually reach a consensus.
I hope in the future there will be a more convenient mechanism for Multi-Model mutual argumentation (rather than manual copy-pasting), which would greatly improve the quality of AI-generated code.
From Software Search to Code Generation: The Agentic Coding Revolution
2025-04-08User Story: RSS Feed Clean-up Journey
Over the past 15 years, I’ve accumulated a substantial collection of RSS feeds, numbering over 200 subscriptions. While RSS usage has dramatically declined in recent years, some of these feeds remain part of my daily reading routine. However, the collection has become cluttered:
- Many feeds have become completely inaccessible
- Some bloggers have stopped updating their sites
- Certain feeds are still active but rarely updated
The Challenge:
- Manual verification of each feed would be tedious and time-consuming
- My RSS reader (News Explorer) lacks feed cleanup functionality
- Alternative solutions like Inoreader require paid subscriptions
- The task remained pending due to lack of efficient solutions
The Agentic Coding Solution:
What was previously a daunting task transformed into a manageable project:
- Total time from requirement writing to completion: ~2 hours
- Automated validation of all feeds
- Generated comprehensive statistics and visualizations
- Successfully categorized feeds into active, inactive, and dead
- Pleasant and efficient development experience
This experience perfectly illustrates how agentic coding can turn a long-postponed task into an achievable solution through clear requirement description and AI-assisted development.
The Traditional Approach
Traditionally, when faced with a specific requirement like validating and analyzing OPML feed subscriptions, the typical workflow would be:
- Search for existing software that might solve the problem
- Evaluate multiple tools and their features
- Choose the closest match, often compromising on exact requirements
- Learn how to use the chosen software
- Deal with limitations and missing features
This process is time-consuming and often results in settling for a solution that doesn’t perfectly match our needs.
The Agentic Coding Paradigm
With agentic coding, the approach transforms dramatically:
- Clearly describe your requirements in natural language
- Let AI understand and break down the problem
- Generate custom code that exactly matches your needs
- Iterate and refine the solution through conversation
Real-World Example: OPML Feed Validator
This project demonstrates the power of agentic coding. Instead of searching for an existing OPML feed validator:
We described our need for a tool that could:
- Validate RSS feeds in an OPML file
- Check feed accessibility
- Analyze update frequencies
- Generate meaningful statistics
- Visualize the results
The AI agent:
- Designed the system architecture
- Implemented the required functionality
- Created visualization components
- Generated comprehensive documentation
- All while following best practices and proper error handling
Benefits of Agentic Coding
- Perfect Fit: Solutions are tailored exactly to your requirements
- Rapid Development: No need to spend time searching and evaluating existing tools
- Full Control: Complete access to the source code for modifications
- Learning Opportunity: Understanding how the solution works through generated code
- Cost-Effective: No need to purchase or subscribe to multiple tools
- Maintenance Freedom: Ability to modify and extend the solution as needs evolve
Future Implications
This shift from “finding” to “generating” solutions represents a fundamental change in how we approach software development. As AI continues to evolve:
- Development will become more requirement-driven than tool-driven
- Custom solutions will become as accessible as off-the-shelf software
- The focus will shift from “what exists” to “what’s possible”
Agentic coding empowers developers and users alike to create exactly what they need, breaking free from the limitations of existing software solutions.
Lessons Learned and Experience
1. The Importance of Clear Requirements
Product thinking and clear requirements are crucial for successful AI-assisted development:
- Clear Vision Leads to Better Code: When requirements are well-defined and specific about how the tool should behave, the AI generates higher quality code
- Product Mindset: Requirement providers need to have a clear understanding of:
- Desired user interactions
- Expected outputs and their formats
- Error handling scenarios
- Performance expectations
- Iterative Refinement: Unclear requirements often lead to multiple iterations and code quality issues
2. Technology Stack Selection Matters
The choice of programming languages and libraries significantly impacts AI-assisted development success:
Language Popularity Impact:
- More widely used languages (like Python) often result in better AI-generated code
- Popular languages have more training data and real-world examples
- In this project, while we chose TypeScript with Deno for learning purposes, Python might have been an easier choice
Library Selection Strategy:
- Popular, widely-used libraries lead to better AI comprehension and implementation
- Example from this project:
- Initial attempt: Using less common
deno_chartlibrary resulted in multiple errors - Successful pivot: Switching to standard SVG generation led to immediate success
- Initial attempt: Using less common
- Lesson: Prefer mainstream libraries over niche ones when working with AI
Best Practices for AI-Assisted Development
Requirements Phase:
- Invest time in detailed requirement documentation
- Include specific examples of desired behavior
- Define clear success criteria
Technology Selection:
- Consider language popularity and ecosystem maturity
- Choose widely-adopted libraries when possible
- Balance learning goals with development efficiency
Development Process:
- Start with core functionality using proven technologies
- Experiment with newer technologies only after basic features are stable
- Be prepared to pivot when encountering AI limitations with specific technologies
This project serves as a practical example of these lessons, demonstrating both the potential and limitations of AI-assisted development while highlighting the importance of making informed technology choices.
The project can be found here.
Getting Started with Deno: A Modern Twist on JavaScript Runtimes
2025-03-28If you’ve been in the JavaScript world for a while, you’ve probably heard of Deno—the runtime that’s been making waves as a “better Node.js.” Built by Ryan Dahl (the original creator of Node.js), Deno takes a fresh approach to running JavaScript and TypeScript, aiming to fix some of Node’s pain points while embracing modern standards. In this post, I’ll walk you through what Deno is, how it works, and how it stacks up against Node.js—especially based on my recent dive into it while tinkering with a Supabase integration.
What is Deno?
Deno is a secure, modern runtime for JavaScript and TypeScript, launched in 2020. It’s designed to be simple, safe, and developer-friendly, with built-in support for TypeScript, ES Modules, and a standard library—no extra tools required. Think of it as Node.js reimagined with lessons learned from the past decade.
Here’s a quick taste of Deno in action:
1 | // main.ts |
Run it with:
1 | deno run --allow-net main.ts |
Boom—a web server in three lines, no npm install or node_modules in sight.
Key Features of Deno
1. TypeScript Out of the Box
Deno runs TypeScript natively—no tsconfig.json or tsc needed. Write your .ts file, run it with deno run, and Deno compiles it in memory. Compare that to Node.js, where you’d need typescript installed and a build step (or ts-node for a quicker dev loop).
2. URL-Based Imports
Forget node_modules. Deno fetches dependencies from URLs:
1 | import { load } from "https://deno.land/std@0.224.0/dotenv/mod.ts"; |
It caches them globally (more on that later) and skips the package manager entirely.
3. Security by Default
Deno won’t let your script touch the network, filesystem, or environment unless you explicitly allow it:
1 | deno run --allow-env --allow-read main.ts |
This is a stark contrast to Node.js, where scripts have free rein unless you sandbox them yourself.
4. Centralized Dependency Cache
Deno stores all dependencies in a single global cache (e.g., ~/.cache/deno/deps on Unix). Run deno info to see where:
1 | deno info |
No per-project node_modules bloating your disk.
5. Standard Library
Deno ships with a curated std library (e.g., https://deno.land/std@0.224.0), covering HTTP servers, file I/O, and even a dotenv module for .env files—stuff you’d normally grab from npm in Node.js.
Deno vs. Node.js: A Head-to-Head Comparison
I recently played with Deno to connect to Supabase, and it highlighted some big differences from Node.js. Here’s how they stack up:
Dependency Management
- Node.js: Uses
npmandpackage.jsonto install dependencies into a localnode_modulesfolder per project. Cloning a repo? Runnpm installevery time.1
npm install @supabase/supabase-js
- Deno: Imports modules via URLs, cached globally at
~/.cache/deno/deps. Clone a Deno repo, and you’re ready to run—no install step.1
import { createClient } from "https://esm.sh/@supabase/supabase-js@2.49.3";
- Winner?: Deno for simplicity, Node.js for isolation (different projects can use different versions of the same module without URL juggling).
TypeScript Support
- Node.js: Requires setup—install
typescript, configuretsconfig.json, and compile to JavaScript (or usets-node). It’s mature but clunky. - Deno: TypeScript runs natively. No config, no build step. Write
.tsand go. - Winner: Deno, hands down, unless you’re stuck on a legacy Node.js workflow.
Configuration Files
- Node.js: Relies on
package.jsonfor dependencies and scripts, often paired withtsconfig.jsonfor TypeScript. - Deno: Optional
deno.jsonfor imports and settings, but not required. My Supabase script didn’t need one—just a.envfile andstd/dotenv. - Winner: Deno for minimalism.
Security
- Node.js: Open by default. Your script can read files or hit the network without warning.
- Deno: Locked down. Want to read
.env? Add--allow-read. Network access?--allow-net. It forced me to think about permissions when connecting to Supabase. - Winner: Deno for safety.
Ecosystem
- Node.js: Massive npm ecosystem—hundreds of thousands of packages. Whatever you need, it’s there.
- Deno: Smaller but growing ecosystem via
deno.land/xand CDNs likeesm.sh. It worked fine for Supabase, but niche libraries might be missing. - Winner: Node.js for sheer volume.
Learning Curve
- Node.js: Familiar to most JavaScript devs, but the setup (npm, TypeScript, etc.) can overwhelm beginners.
- Deno: Fresh approach, but URL imports and permissions might feel alien if you’re Node.js-native.
- Winner: Tie—depends on your background.
A Real-World Example: Supabase with Deno
Here’s how I set up a Supabase client in Deno:
1 | import { createClient } from "https://esm.sh/@supabase/supabase-js@2.49.3"; |
Run it:
1 | deno run --allow-env --allow-read main.ts |
.envfile:SUPABASE_URLandSUPABASE_ANON_KEY(grabbed from Supabase’s dashboard—not my database password!).- VS Code linting needed the Deno extension and a
deno cache main.tsto quiet TypeScript errors.
In Node.js, I’d have installed @supabase/supabase-js via npm, set up a dotenv package, and skipped the permissions flags. Deno’s way felt leaner but required tweaking for editor support.
Should You Use Deno?
- Use Deno if:
- You love TypeScript and hate build steps.
- You want a secure, minimal setup for small projects or experiments.
- You’re intrigued by a modern take on JavaScript runtimes.
- Stick with Node.js if:
- You need the npm ecosystem’s depth.
- You’re working on a legacy project or with a team entrenched in Node.
- You prefer per-project dependency isolation.
Wrapping Up
Deno’s not here to kill Node.js—it’s a different flavor of the same JavaScript pie. After messing with it for Supabase, I’m hooked on its simplicity and TypeScript support, but I’d still reach for Node.js on bigger, ecosystem-heavy projects. Try it yourself—spin up a Deno script, check your cache with deno info, and see if it clicks for you.
What’s your take? Node.js veteran or Deno newbie? Let me know in the comments!
This post covers Deno’s core concepts, contrasts it with Node.js, and ties in our Supabase example for a practical angle. Feel free to tweak the tone or add more details if you’re aiming for a specific audience! Want me to adjust anything?
How to Generate a VSIX File from VS Code Extension Source Code
2024-12-12As I’ve been using Windsurf as my primary code editor, I encountered a situation where the vs-picgo extension wasn’t available in the Windsurf marketplace. This necessitated the need to manually package the extension from its source code. This guide documents the process of generating a VSIX file for VS Code extensions, which can then be installed manually in compatible editors like Windsurf.
In this guide, I’ll walk you through the process of generating a VSIX file from a VS Code extension’s source code. We’ll use the popular vs-picgo extension as an example.
Prerequisites
Before we begin, make sure you have the following installed:
- Node.js (version 12 or higher)
- npm (comes with Node.js)
Step 1: Install Required Tools
First, we need to install two essential tools:
yarn: A package manager that will handle our dependenciesvsce: The VS Code Extension Manager tool that creates VSIX packages
1 | # Install Yarn globally |
Step 2: Prepare the Project
Clone or download the extension source code:
1
2git clone https://github.com/PicGo/vs-picgo.git
cd vs-picgoInstall project dependencies:
1
yarn install
This command will:
- Read the
package.jsonfile - Install all required dependencies
- Create or update the
yarn.lockfile
Note: The
yarn.lockfile is important! Don’t delete it as it ensures consistent installations across different environments.
Step 3: Build the Extension
Build the extension using the production build command:
1 | yarn build:prod |
This command typically:
- Cleans the previous build output
- Compiles TypeScript/JavaScript files
- Bundles all necessary assets
- Creates the
distdirectory with the compiled code
In vs-picgo’s case, the build process:
- Uses
esbuildfor fast bundling - Creates both extension and webview bundles
- Generates source maps (disabled in production)
- Optimizes the code for production use
Step 4: Package the Extension
Finally, create the VSIX file:
1 | vsce package |
This command:
- Runs any pre-publish scripts defined in
package.json - Validates the extension manifest
- Packages all required files into a VSIX file
- Names the file based on the extension’s name and version (e.g.,
vs-picgo-2.1.6.vsix)
The resulting VSIX file will contain:
- Compiled JavaScript files
- Assets (images, CSS, etc.)
- Extension manifest
- Documentation files
- License information
What’s Inside the VSIX?
The VSIX file is essentially a ZIP archive with a specific structure. For vs-picgo, it includes:
1 | vs-picgo-2.1.6.vsix |
Installing the Extension
You can install the generated VSIX file in VS Code or any compatible editor by:
- Opening VS Code/Windsurf/Cursor …
- Going to the Extensions view
- Clicking the “…” menu (More Actions)
- Selecting “Install from VSIX…”
- Choosing your generated VSIX file
Troubleshooting
If you encounter any issues:
Missing dist directory error:
- This is normal on first build
- The build process will create it automatically
Dependency errors:
- Run
yarn installagain - Check if you’re using the correct Node.js version
- Run
VSIX packaging fails:
- Verify your
package.jsonis valid - Ensure all required files are present
- Check the extension manifest for errors
- Verify your
Conclusion
Building a VS Code extension VSIX file is straightforward once you have the right tools installed. The process mainly involves installing dependencies, building the source code, and packaging everything into a VSIX file.
Remember to keep your yarn.lock file and always build in production mode before packaging to ensure the best performance and smallest file size for your users.
Happy extension building! 🚀
What is DBOS and What Should We Expect
2024-11-14Introduction
The computing world is witnessing a paradigm shift in how we think about operating systems. A team of researchers has proposed DBOS (Database-Oriented Operating System), a radical reimagining of operating system architecture that puts data management at its core. But what exactly is DBOS, and why should we care?
What is DBOS?
DBOS is a novel operating system architecture that treats data management as its primary concern rather than traditional OS functions like process management and I/O. The key insight behind DBOS is that modern applications are increasingly data-centric, yet our operating systems still follow designs from the 1970s that prioritize computation over data management.
Instead of treating databases as just another application, DBOS makes database technology the fundamental building block of the operating system itself. This means core OS functions like process scheduling, resource management, and system monitoring are implemented using database principles and technologies.
Who is behind DBOS?
DBOS is a collaborative research project involving almost twenty researchers across multiple institutions including MIT, Stanford, UW-Madison, Google, VMware, and other organizations. The project is notably led by database pioneer Michael Stonebraker, who is an ACM Turing Award winner (2014) and Professor Emeritus at UC Berkeley, currently affiliated with MIT.
Key institutions and researchers involved include:
- MIT: Michael Stonebraker, Michael Cafarella, Çağatay Demiralp, and others
- Stanford: Matei Zaharia, Christos Kozyrakis, and others
- UW-Madison: Xiangyao Yu
- Industry partners: Researchers from Google, VMware, and other organizations
The people behind DBOS can be found at DBOS Project.
Ultimate Goal
The ultimate goal of DBOS is to create an operating system that is data-centric and data-driven, the OS is on top of a DBMS, not like today’s DBMS on top of the OS.
ALL system data should reside in the DBMS.
- Replace the “everything is a file” mantra with “everything is a table”
- All system state and metadata stored in relational tables
- All changes to OS state should be through database transactions
- DBMS provides All functions that a DBMS can do, for example, files are blobs and tables in the DBMS.
- SQL-based interface for both application and system data access
- To achieve very high performance, the DBMS must leverage sophisticated caching and parallelization strategies and compile repetitive queries into machine code.
Benefits
- Strong Security and Privacy
- Native GDPR compliance through data-centric design
- Attribute-based access control (ABAC)
- Complete audit trails and data lineage
- Privacy by design through unified data management
- Fine-grained access control at the data level
- Enhanced monitoring and threat detection
- Simplified compliance with regulatory requirements
- Built-in data encryption and protection mechanisms
- Enhanced Performance and Efficiency
- Optimized resource allocation through database-driven scheduling
- Reduced data movement and copying
- Better cache utilization through database techniques
- Intelligent workload management
- Advanced query optimization for system operations
- Improved resource utilization through data-aware decisions
- Reduced system overhead through unified architecture
- Better support for modern hardware architectures
- Improved Observability and Management
- Comprehensive system-wide monitoring
- Real-time analytics on system performance
- Easy troubleshooting through SQL queries
- Better capacity planning capabilities
- Unified logging and debugging interface
- Historical analysis of system behavior
- Predictive maintenance capabilities
- Simplified system administration
- Advanced Application Support
- Native support for distributed applications
- Better handling of microservices architecture
- Simplified state management
- Enhanced support for modern cloud applications
- Built-in support for data-intensive applications
- Improved consistency guarantees
- Better transaction management
- Simplified development of distributed systems
Technical Implementation
DBOS proposes implementing core OS functions using database principles:
- Process Management: Processes and their states managed as database tables
- Resource Scheduling: SQL queries and ML for intelligent scheduling decisions
- System Monitoring: Metrics collection and analysis through database queries
- Security: Access control and auditing via database mechanisms
- Storage: File system metadata stored in relational tables
- Networking: Network state and routing managed through database abstractions
What Should We Expect?
Near-term Impact
- Proof of Concept: The researchers are working on demonstrating DBOS’s capabilities through specific use cases like log processing and accelerator management.
- Performance Improvements: Early implementations might show significant improvements in data-intensive workloads.
- Development Tools: New tools and frameworks that leverage DBOS’s database-centric approach.
Long-term Possibilities
Cloud Native Integration: DBOS could become particularly relevant for cloud computing environments where data management is crucial.
- AI/ML Operations: Better support for AI and machine learning workloads through intelligent resource management.
- Privacy-First Computing: A new standard for building privacy-compliant systems from the ground up.
Challenges Ahead
Several technical and practical challenges need to be addressed:
- Performance
- Minimizing database overhead for system operations
- Optimizing query performance for real-time OS operations
- Efficient handling of high-frequency system events
- Compatibility
- Supporting existing applications and system calls
- Maintaining POSIX compliance where needed
- Migration path for legacy systems
- Distributed Systems
- Maintaining consistency across distributed nodes
- Handling network partitions and failures
- Scaling database operations across clusters
- Adoption
- Convincing stakeholders to adopt radical architectural changes
- Training developers in the new paradigm
- Building an ecosystem of compatible tools and applications
Conclusion
DBOS represents a bold reimagining of operating system design for the data-centric world. While it’s still in its early stages, the potential benefits for security, privacy, and developer productivity make it an exciting project to watch. As data continues to grow in importance, DBOS’s approach might prove to be prescient.
The success of DBOS will largely depend on how well it can demonstrate its advantages in real-world scenarios and whether it can overcome the inherent challenges of introducing such a fundamental change to system architecture. For developers, system administrators, and anyone interested in the future of computing, DBOS is definitely worth keeping an eye on.
Whether DBOS becomes the next evolution in operating systems or remains an interesting academic exercise, its ideas about putting data management at the center of system design will likely influence future OS development.
References
M. Stonebraker et al., “DBOS: A DBMS-oriented Operating System,” Proceedings of the VLDB Endowment, Vol. 15, No. 1, 2021.
https://www.vldb.org/pvldb/vol15/p21-stonebraker.pdfDBOS Project Official Website, MIT CSAIL and Stanford University.
https://dbos-project.github.io/X. Yu et al., “A Case for Building Operating Systems with Database Technology,” Proceedings of the 12th Conference on Innovative Data Systems Research (CIDR ‘22), 2022.
https://www.cidrdb.org/cidr2022/papers/p82-yu.pdfDBOS Research Group Publications.
https://dbos-project.github.io/papers/
These references provide detailed technical information about DBOS’s architecture, implementation, and potential impact on the future of operating systems. The papers discuss various aspects from system design to performance evaluation, security considerations, and practical applications.
Some Misconceptions About Database Performance - Application Concurrent Requests, Database Connections, and Database Connection Pools
2024-08-21Let’s start with a chart from a database stress test result.
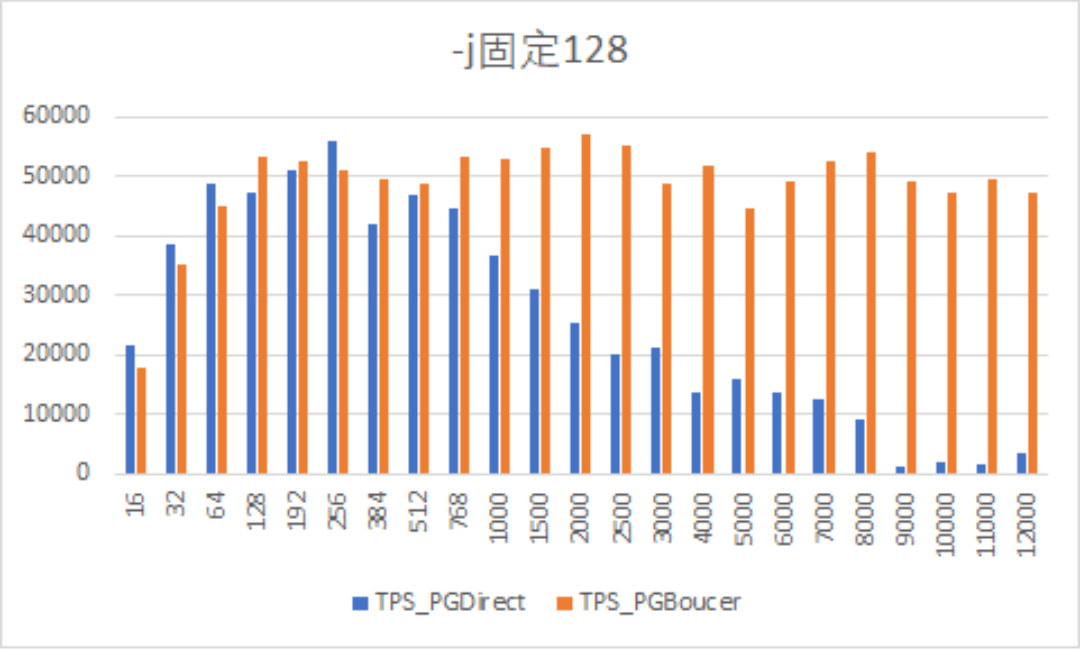
In the chart above, the X-axis represents the number of concurrent connections, and the Y-axis represents the TPS (Transactions Per Second) provided by the database. The stress testing tool used is pgbench, and the database is a single instance of PostgreSQL 16. TPS_PGDirect represents the TPS when pgbench directly sends the load to PostgreSQL, while TPS_PGBouncer represents the TPS when pgbench sends the load to the PGBouncer database connection pool.
We can clearly see that when the number of connections exceeds 256, the TPS begins to gradually decline when the load is sent directly to the database. When the number of connections eventually rises to over 8000, the database is almost at a standstill. However, when using PGBouncer, the TPS remains stable and excellent, with the database consistently providing high TPS regardless of the number of connections.
Many people might conclude from this chart that if the concurrent connections increase beyond a certain threshold, PostgreSQL becomes inadequate, and PGBouncer must be used to improve performance.
Some users may attempt to conduct various hardware environment combination tests to derive a reference threshold number to guide at what pressure PostgreSQL can cope, and once it exceeds a certain pressure, PGBouncer should be enabled.
So, is this conclusion correct? And does testing out a threshold number have real guiding significance?
Understanding Concurrent Performance
To determine how many concurrent business requests a database can handle, we should focus on the Y-axis from the test chart above, rather than the X-axis. The Y-axis TPS represents the number of transactions the database can process per second, while the X-axis connection count is merely the database connection number we configured ourselves (which can be simply understood as the max_connections parameter value). We can observe that at 256 connections, the direct database stress test with pgbench allows the database to provide over 50,000 TPS, which is actually almost the highest number in the entire stress test (WITHOUT PGBouncer). Subsequent tests using PGBouncer, this number was not significantly exceeded. Therefore, PGBouncer is not a weapon to improve database performance.
What is performance? Performance means: for a determined business transaction pressure (how much work a business transaction needs to handle, such as how much CPU, memory, and IO it consumes), the more transactions the database can execute, the higher the performance. In the chart above, this is represented by the Y-axis TPS (Transactions Per Second).
For example, suppose a user request (Application Request) requires executing 5 transactions from start to finish, and assume these transactions consume similar amounts of time (even if there are differences, we can always get the average transaction runtime in a system). In this case, 50,000 TPS means the database can handle 10,000 user requests per second, which can be simply understood as handling 10,000 concurrent users. If TPS rises to 100,000, the database can handle 20,000 concurrent users; if TPS drops to 10,000, it can only handle 2,000 concurrent users. This is a simple calculation logic, and in this description, we did not mention anything about database connections (User Connections).
So why does it seem like PGBouncer improves performance when the number of connections continues to increase? Because in this situation, PGBouncer acts as a limiter on database connections, reducing the extra overhead caused by the database/operating system handling too many connections, allowing the database and operating system to focus on processing the business requests sent from each connection, and enabling user requests exceeding the connection limit to share database connections. What PGBouncer does is: if your restaurant can only provide 10 tables, then I only allow 10 tables of guests to enter, and other guests have to wait outside.
However, why should we let 100 tables of guests rush into the restaurant all at once? Without PGBouncer, can’t we control allowing only 10 tables of guests to enter? In modern applications, application-side connection pools are more commonly used, such as connection pools in various middleware software (Weblogic, WebSphere, Tomcat, etc.) or dedicated JDBC connection pools like HikariCP.
Exceeding the number of connections that can be handled is unnecessary. When the database is already at its peak processing capacity, having more connections will not improve overall processing capability; instead, it will slow down the entire database.
To summarize the meaning of the chart above more straightforwardly: when the total number of database connections is at 256, the database reaches its peak processing capacity, and direct database connections can provide 50,000 TPS without any connection pool. If 50,000 TPS cannot meet the application’s concurrent performance requirements, increasing the number of connections will not help. But if connections are increased (wrongly, without any other control), a layer of connection pool like PGBouncer can be added as a connection pool buffer to keep performance stable at around 50,000 TPS.
So, do we have any reason to arbitrarily increase the number of connections? No. What we need to do is: allow the database to open only the number of connections within its processing capacity and enable these connections to be shared by more user requests. When the restaurant size is fixed, the higher the turnover rate, the higher the restaurant’s daily revenue.
How to Ask Questions About Performance
Instead of asking: how can we ensure the database provides sufficient TPS with 4000 connections, we should ask: how can we ensure the database provides 50,000 TPS.
Because the number of connections is not a performance metric, it is merely a parameter configuration option.
In the example above, a connection count of 4000 or 8000 is not a fixed value, nor is it an optimized value. We cannot try to do more additional database optimizations on an unoptimized, modifiable parameter setting, as this may lead to a reversal of priorities. If we can already provide maximum processing capacity with 256 fully loaded database connections, why optimize a database with more than 256 connections? We should ensure the database always runs at full capacity with a maximum of 256 connections.
Now, our question about performance can be more specific. Suppose we have multiple sets of database servers with different configurations; what should the fully loaded connection count be for each set to achieve optimal processing capacity?
This requires testing. However, we will ultimately find that this fully loaded connection count is usually related only to the database server’s hardware resources, such as the number of CPU cores, CPU speed, memory size, storage speed, and the bandwidth and latency between storage and host.
Is Database Application Performance Only Related to Hardware Resources?
Of course not. Concurrent performance (P) = Hardware processing capability (H) / Business transaction pressure (T).
As mentioned earlier, the performance metric TPS is for a “determined business transaction pressure,” meaning a determined T value.
When the T value is determined, we can only improve the H value to further enhance the P value. Conversely, there is naturally another optimization approach: reducing the T value. There are various ways to reduce the T value, such as adding necessary indexes, rewriting SQL, using partitioned tables, etc. The optimization plan should be formulated based on where the T value is consumed most, which is another topic.
Conclusion
To answer the two initial questions:
- If concurrent connections increase beyond a certain threshold, PostgreSQL becomes inadequate, and PGBouncer must be used to improve performance. Is this conclusion correct?
If we must create more connections to the database than the hardware processing capacity for certain hardware resources, using PGBouncer can stabilize performance. However, we have no reason to create more connections than the hardware processing capacity. We have various means to control the maximum number of connections the database can open, and various middleware solutions can provide connection pools. From this perspective, PGBouncer does not improve database performance; it merely reduces concurrency conflicts, doing what any connection pool software can do.
- Is it meaningful to attempt various hardware environment combination tests to derive a reference threshold number to guide at what pressure PostgreSQL can cope, and once it exceeds a certain pressure, PGBouncer should be enabled?
It has some significance, but simple stress tests like pgbench are not enough to guide real applications. Concurrent performance (P) = Hardware processing capability (H) / Business transaction pressure (T). Testing in a determined hardware environment means the H value is fixed, so we should focus on T during testing. The T value provided by pgbench is a very simple transaction pressure (only four tables, simple CRUD operations), and the P value tested under this pressure can only be used as a reference. To guide application deployment, typical transaction pressure of the application itself must be abstracted for testing to have guiding significance.
Flashback Features in MogDB
2024-06-15What is Database Flashback
The flashback capability of a database allows users to query the contents of a table at a specific point in the past or quickly restore a table or even the entire database to a time before an erroneous operation. This feature can be extremely useful, and sometimes even a lifesaver.
Database flashback capabilities are generally divided into three levels:
- Row-level Flashback: Also known as flashback query, this typically involves using a SELECT statement to retrieve data from a table as it was at a specific point in time, such as right before a DELETE command was issued.
- Table-level Flashback: Also known as flashback table, this usually involves using specialized DDL statements to recreate a table from the recycle bin. This is often used to recover from a TRUNCATE TABLE or DROP TABLE operation.
- Database-level Flashback: Also known as flashback database, this involves using specialized DDL statements to restore the entire database to a previous point in time. Unlike PITR (Point-In-Time Recovery) which involves restoring from backups, flashback database is faster as it does not require restoring the entire database from backup sets.
In MogDB version 5.0, only flashback query and flashback table have been implemented so far. Flashback database has not yet been implemented (Oracle has supported flashback database since version 10g).
Scenario
Imagine a regrettable scenario (Note: do not run the DELETE SQL command in a production environment).
You have a table that records account names and account balances.
1 | MogDB=# select * from accounts; |
You intended to execute an SQL command to delete account records with a balance of 99 units. Normally, this should delete one record. To demonstrate, let’s use SELECT instead of DELETE.
1 | MogDB=# select * from accounts where amount=99; |
However, the minus sign “-“ and the equals sign “=” are adjacent on the keyboard, and you have fat fingers, so you accidentally pressed the minus sign. As a result, the command you sent to the database looks like this:
1 | delete from accounts where amount-99; |
For demonstration purposes, we’ll still use SELECT instead of DELETE.
1 | MogDB=# select * from accounts where amount-99; |
A terrifying thing happens: all data except the record with a balance exactly equal to 99 is returned. This means that if this were the DELETE command mentioned above, you would have deleted all accounts with a balance not equal to 99.
The good news is that starting from MogDB version 3.0, validation for such dangerous syntax involving the minus sign has been added. Now, executing the same SQL will result in an error.
1 | MogDB=# delete from accounts where amount-99; |
However, in the community editions of openGauss, MySQL, or MariaDB, such dangerous syntax can still be executed normally.
1 | gsql ((openGauss 6.0.0-RC1 build ed7f8e37) compiled at 2024-03-31 12:41:30 commit 0 last mr ) |
No matter what kind of erroneous operation occurs, suppose a data deletion error really happens. In MogDB, you still have the flashback feature available for recovery.
Flashback Feature in MogDB
The flashback feature and its related implementations have undergone some changes since MogDB version 3.0.
Applicable Only to Ustore Storage Engine:
The flashback feature only works for tables using the ustore storage engine. The default astore no longer supports flashback queries. Therefore, you need to set
enable_ustore=on. This parameter is off by default, and changing it requires a database restart to take effect.1
2
3MogDB=# alter system set enable_ustore=on;
NOTICE: please restart the database for the POSTMASTER level parameter to take effect.
ALTER SYSTEM SETSetting
undo_retention_time:This parameter specifies the retention time for old version data in the rollback segment, equivalent to the allowable time span for flashback queries. The default value is 0, meaning any flashback query will encounter a “restore point not found” error. Changing this parameter does not require a database restart.
1
2MogDB=# alter system set undo_retention_time=86400; -- 86400 seconds = 24 hours
ALTER SYSTEM SETEnabling Database Recycle Bin for Truncate or Drop Operations:
To flashback a table from a truncate or drop operation, you need to enable the database recycle bin by setting
enable_recyclebin=on. This parameter is off by default, and changing it does not require a database restart.1
2MogDB=# alter system set enable_recyclebin=on;
ALTER SYSTEM SET
Creating and Populating the Ustore Table
Create a ustore-based accounts table and insert some test data.
1 | MogDB=# create table accounts (name varchar2, amount int) with (storage_type=ustore); |
Simulating an Erroneous Deletion
Now, due to some erroneous operation, you delete all account records with amounts not equal to 99.
1 | MogDB=# delete from accounts where amount<>99; |
Flashback Query
When you realize the mistake, it might be 1 minute or 1 hour later. As long as it is within 24 hours (due to the undo_retention_time setting), you can recover the data.
Check the current timestamp and estimate the timestamp at the time of the erroneous operation. For simplicity, let’s assume you noted the system’s timestamp before issuing the delete command.
1 | MogDB=# select sysdate; |
Issue a flashback query to retrieve the data as it was at the specified timestamp.
1 | MogDB=# select * from accounts timecapsule TIMESTAMP to_timestamp('2024-06-13 18:40:18','YYYY-MM-DD HH24:MI:SS'); |
Recovering Data
You can recover the data by creating a temporary table with the flashback query results and then inserting the data back into the original table.
1 | MogDB=# create table tmp_accounts as select * from accounts timecapsule TIMESTAMP to_timestamp('2024-06-13 18:40:18','YYYY-MM-DD HH24:MI:SS') where amount<>99; |
Alternatively, if no new data has been added to the table after the erroneous operation, you can use the timecapsule table command to flashback the entire table to the specified timestamp.
1 | MogDB=# timecapsule table accounts to TIMESTAMP to_timestamp('2024-06-13 18:40:18','YYYY-MM-DD HH24:MI:SS'); |
Recovering from Truncate or Drop Table
If you accidentally issue a TRUNCATE or DROP command, In this situation, the before commands don’t help because the data has been truncated.
1 | MogDB=# truncate table accounts; |
For TRUNCATE or DROP TABLE operations, use the to before keyword to recover the table from the recycle bin.
1 | MogDB=# timecapsule table accounts to before truncate; |
Similarly, if the table was dropped, you can recover it from the recycle bin using the same to before keyword.
1 | MogDB=# drop table accounts; |
Conclusion
MogDB’s flashback feature is an essential tool for recovering from accidental data deletions, truncations, or drops. By enabling the ustore storage engine, setting an appropriate undo_retention_time, and activating the recycle bin, you can leverage flashback queries and the timecapsule command to restore your data efficiently. These features ensure that you can maintain data integrity and quickly recover from human errors, providing robust data protection and operational resilience.
Exploring Oracle Compatibility in MogDB (Series I) - Data Dictionary
2024-06-06Install PTK
PTK is the optimal tool for installing the MogDB database (an enterprise-grade commercial distribution based on openGauss) or the openGauss database, offering a seamless and smooth installation experience.
To install PTK, simply run the following command:
1 | curl --proto '=https' --tlsv1.2 -sSf https://cdn-mogdb.enmotech.com/ptk/install.sh | sh |
This command will automatically install PTK in the user’s home directory under $HOME/.ptk. This directory will serve as the working directory for PTK, storing cache files, metadata information, cluster configuration information, backup information, and other related files. Additionally, the installation command will add the path $HOME/.ptk/bin to the PATH environment variable in the corresponding shell profile file, enabling the user to use the ptk command directly after logging into the server. In this tutorial, we installed PTK using the root user, although this is not mandatory.
For more detailed PTK installation instructions, please refer to: PTK Installation Guide.
The environment used for this series of articles is CentOS 7.6 for x86-64. MogDB must currently run on a Linux operating system. If you wish to install MogDB on macOS or Windows, you can do so using container deployment. For more information, refer to: Container-based MogDB Installation
To check your CentOS version, you can use the following command:
1 | # cat /etc/centos-release |
MogDB can also run on ARM architecture CPUs. You can list all supported CPU brands using the ptk candidate cpu command:
1 | # ptk candidate cpu |
If PTK notifies you of a new version while running any command, you can upgrade it directly using the ptk self upgrade command.
1 | # ptk ls |
Install MogDB
With PTK, you can easily create multiple MogDB instances on a single server. Each MogDB instance can be assigned to a different operating system user, allowing you to manage multiple database instances with a single PTK installation.
To quickly create a test database without any configuration, you can use the ptk demo command:
1 | # ptk demo |
The ptk demo command accomplishes the following tasks:
- Creates an operating system user named
demo_user_kVP. - Creates a single-instance MogDB database of the latest version (currently 5.0.7).
- Sets the database to listen on port 26000. Before running the
ptk democommand, ensure that port 26000 is not occupied by other applications. - Create an initial database user with the same name as the OS user:
demo_user_kVP. Also, create a monitor user namedmogdb. Both users will have their initial passwords specified in the “Database Detail” section. - Creates two test databases:
oracle_compatibilityin Oracle-compatible mode andpostgres_compatibilityin PostgreSQL-compatible mode. - For the automatically created
oracle_compatibilitydatabase, the following enhancements are also performed:Installs the mogila dataset. For more information about this dataset, refer to: Using Sample Dataset Mogila
Installs the
whaleplugin, which provides extensive Oracle compatibility features. For more information on the Whale plugin, refer to: whaleInstalls the
compat-toolsutility, which supplements thewhaleplugin with additional Oracle compatibility features that are not yet implemented, such as Oracle-compatible data dictionary views. For more information oncompat-tools, refer to: enmotech/compat-toolsNote:
compat-toolsonly work within a single database. This means that if you install compat-tools in theoracle_compatibilitydatabase (as is done automatically by theptk democommand), you will only be able to query the corresponding Oracle-compatible data dictionary views when logged into that database. If you want to use these views in another database, you must install compat-tools in that database as well. For example, if you want to query Oracle-compatible data dictionary views in thepostgresdatabase, you need to downloadcompat-toolsseparately from enmotech/compat-tools then run the following command:1
gsql -h 127.0.0.1 -p 26000 -d postgres -f runMe.sql
Exploring Oracle-Compatible Data Dictionary in MogDB
Switch to the operating system user associated with the demo database. You can log in to the database using the gsql command.
Note: If you want to connect to the database remotely, you should use the mogdb user. The ptk demo command creates two users in the database. One starts with demo_user_, which is the initial user. Due to MogDB’s enhanced security features, the initial user is not allowed to connect remotely. The other user is mogdb, which can be used for remote connections. The initial password for the users is displayed at the end of the ptk demo command output. Additionally, you should modify the pg_hba.conf file to allow remote connections. For more information, refer to: Connecting to a Database Remotely.
1 | # ptk ls |
All these tables come from the Mogila test dataset.
Compat-tools brings a large number of Oracle-compatible data dictionary views (refer to: Oracle-Compatible Views). Here are some simple examples.
1 | -- sysdate function and dual table is supported |
Note: Due to significant differences in the underlying structure between MogDB and Oracle, these Oracle-compatible views may not include all the fields present in the corresponding Oracle database views.
To be continued:
- Exploring Oracle Compatibility in MogDB (Series II) - System Functions
- Exploring Oracle Compatibility in MogDB (Series III) - DBMS Packages
Working Mechanism of synchronous_standby_names in MogDB
2024-06-05In MogDB, the parameter synchronous_standby_names is used to configure synchronous replication settings. When this parameter is set to '*'(default setting), it indicates that any available standby server can be used as a synchronous standby. This configuration allows any currently connected standby to be utilized as a synchronous standby without explicitly specifying the standby’s name.
Working Mechanism
When synchronous_standby_names is set to '*', MogDB’s synchronous replication mechanism selects the synchronous standby through the following steps:
Initial Connection: When the primary server starts or the parameter is changed, the primary server accepts all connected standby servers.
Synchronous Standby Confirmation:
- The primary server sends a synchronization request to all connected standby servers.
- Each standby server, upon receiving the request, confirms it and reports its status back to the primary server.
Selecting the Synchronous Standby:
- The primary server selects the earliest responding standby server(s) as the synchronous standby.
- This selection process is dynamic, meaning that if new standbys connect or current synchronous standbys disconnect, the primary server will reselect the synchronous standby.
Priority and Behavior
- No Priority Order: Since
'*'denotes any standby, all standbys have the same priority. The primary server simply selects the earliest responding standby as the synchronous standby. - Dynamic Adjustment: If a synchronous standby disconnects, the primary server automatically selects the next responding standby as the new synchronous standby, ensuring the continuity and reliability of synchronous replication.
- Concurrent Management: If multiple standbys connect simultaneously, the primary server can handle these concurrent connections and select the synchronous standby based on the confirmation of synchronization requests.
Configuration Example and Usage
Suppose we have one primary server and three standby servers (standby1, standby2, and standby3). In the configuration file postgresql.conf, set synchronous_standby_names to '*':
1 | synchronous_standby_names = '*' |
Scenario Analysis
Selection at Startup:
- When the primary server starts, all connected standby servers send heartbeat signals and wait for the primary server’s synchronization request.
- The primary server selects the earliest responding standby as the synchronous standby.
Runtime Changes:
- If the current synchronous standby
standby1disconnects, the primary server automatically selects the next responding standbystandby2as the new synchronous standby. - If a new standby
standby3connects to the primary server and there is no current synchronous standby, the primary server selectsstandby3as the synchronous standby.
- If the current synchronous standby
Dynamic Adjustment
If we start the primary server and three standby servers, setting synchronous_standby_names = '*', the following state transitions are possible:
- Initial State: All standbys (
standby1,standby2, andstandby3) connect, and the primary server selects the earliest responding standbystandby1as the synchronous standby. standby1Disconnects: The primary server automatically selects the next responding standbystandby2as the new synchronous standby.- New Standby Connection: A new standby
standby4connects; the primary server will not change the current synchronous standby unlessstandby2disconnects.
Summary
When synchronous_standby_names is set to '*', MogDB dynamically selects any currently available standby as the synchronous standby. This provides a flexible and highly available synchronous replication mechanism without requiring administrators to manually specify the standby names. The selection process is based on standby response times and automatically adjusts during runtime to ensure the continuity and reliability of synchronous replication.