
Some Misconceptions About Database Performance - Application Concurrent Requests, Database Connections, and Database Connection Pools
2024-08-21Let’s start with a chart from a database stress test result.
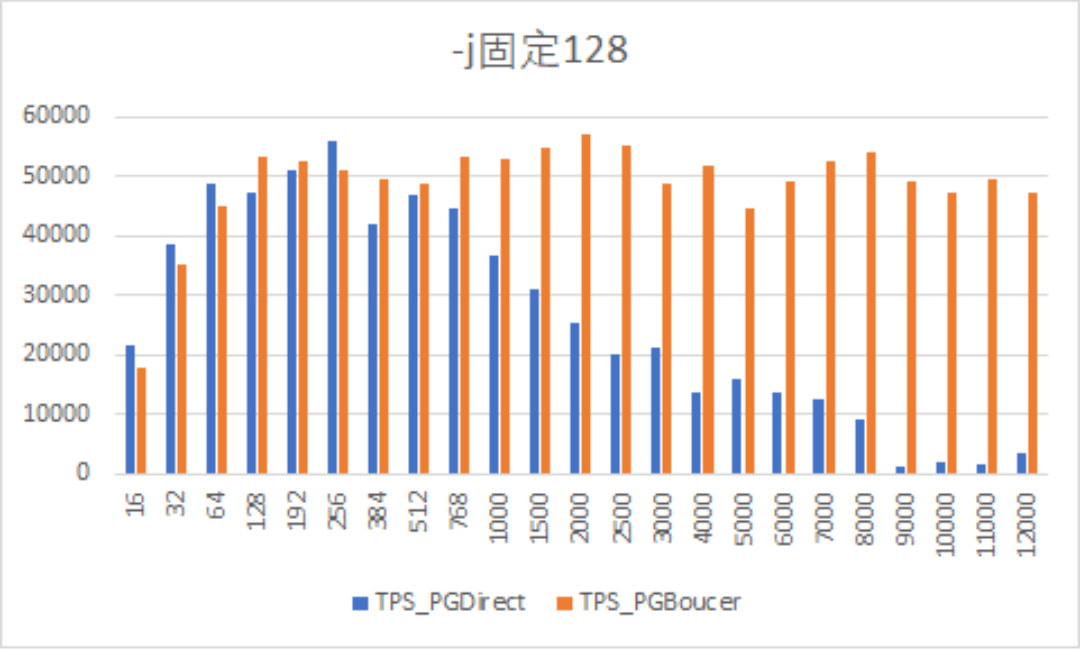
In the chart above, the X-axis represents the number of concurrent connections, and the Y-axis represents the TPS (Transactions Per Second) provided by the database. The stress testing tool used is pgbench, and the database is a single instance of PostgreSQL 16. TPS_PGDirect represents the TPS when pgbench directly sends the load to PostgreSQL, while TPS_PGBouncer represents the TPS when pgbench sends the load to the PGBouncer database connection pool.
We can clearly see that when the number of connections exceeds 256, the TPS begins to gradually decline when the load is sent directly to the database. When the number of connections eventually rises to over 8000, the database is almost at a standstill. However, when using PGBouncer, the TPS remains stable and excellent, with the database consistently providing high TPS regardless of the number of connections.
Many people might conclude from this chart that if the concurrent connections increase beyond a certain threshold, PostgreSQL becomes inadequate, and PGBouncer must be used to improve performance.
Some users may attempt to conduct various hardware environment combination tests to derive a reference threshold number to guide at what pressure PostgreSQL can cope, and once it exceeds a certain pressure, PGBouncer should be enabled.
So, is this conclusion correct? And does testing out a threshold number have real guiding significance?
Understanding Concurrent Performance
To determine how many concurrent business requests a database can handle, we should focus on the Y-axis from the test chart above, rather than the X-axis. The Y-axis TPS represents the number of transactions the database can process per second, while the X-axis connection count is merely the database connection number we configured ourselves (which can be simply understood as the max_connections parameter value). We can observe that at 256 connections, the direct database stress test with pgbench allows the database to provide over 50,000 TPS, which is actually almost the highest number in the entire stress test (WITHOUT PGBouncer). Subsequent tests using PGBouncer, this number was not significantly exceeded. Therefore, PGBouncer is not a weapon to improve database performance.
What is performance? Performance means: for a determined business transaction pressure (how much work a business transaction needs to handle, such as how much CPU, memory, and IO it consumes), the more transactions the database can execute, the higher the performance. In the chart above, this is represented by the Y-axis TPS (Transactions Per Second).
For example, suppose a user request (Application Request) requires executing 5 transactions from start to finish, and assume these transactions consume similar amounts of time (even if there are differences, we can always get the average transaction runtime in a system). In this case, 50,000 TPS means the database can handle 10,000 user requests per second, which can be simply understood as handling 10,000 concurrent users. If TPS rises to 100,000, the database can handle 20,000 concurrent users; if TPS drops to 10,000, it can only handle 2,000 concurrent users. This is a simple calculation logic, and in this description, we did not mention anything about database connections (User Connections).
So why does it seem like PGBouncer improves performance when the number of connections continues to increase? Because in this situation, PGBouncer acts as a limiter on database connections, reducing the extra overhead caused by the database/operating system handling too many connections, allowing the database and operating system to focus on processing the business requests sent from each connection, and enabling user requests exceeding the connection limit to share database connections. What PGBouncer does is: if your restaurant can only provide 10 tables, then I only allow 10 tables of guests to enter, and other guests have to wait outside.
However, why should we let 100 tables of guests rush into the restaurant all at once? Without PGBouncer, can’t we control allowing only 10 tables of guests to enter? In modern applications, application-side connection pools are more commonly used, such as connection pools in various middleware software (Weblogic, WebSphere, Tomcat, etc.) or dedicated JDBC connection pools like HikariCP.
Exceeding the number of connections that can be handled is unnecessary. When the database is already at its peak processing capacity, having more connections will not improve overall processing capability; instead, it will slow down the entire database.
To summarize the meaning of the chart above more straightforwardly: when the total number of database connections is at 256, the database reaches its peak processing capacity, and direct database connections can provide 50,000 TPS without any connection pool. If 50,000 TPS cannot meet the application’s concurrent performance requirements, increasing the number of connections will not help. But if connections are increased (wrongly, without any other control), a layer of connection pool like PGBouncer can be added as a connection pool buffer to keep performance stable at around 50,000 TPS.
So, do we have any reason to arbitrarily increase the number of connections? No. What we need to do is: allow the database to open only the number of connections within its processing capacity and enable these connections to be shared by more user requests. When the restaurant size is fixed, the higher the turnover rate, the higher the restaurant’s daily revenue.
How to Ask Questions About Performance
Instead of asking: how can we ensure the database provides sufficient TPS with 4000 connections, we should ask: how can we ensure the database provides 50,000 TPS.
Because the number of connections is not a performance metric, it is merely a parameter configuration option.
In the example above, a connection count of 4000 or 8000 is not a fixed value, nor is it an optimized value. We cannot try to do more additional database optimizations on an unoptimized, modifiable parameter setting, as this may lead to a reversal of priorities. If we can already provide maximum processing capacity with 256 fully loaded database connections, why optimize a database with more than 256 connections? We should ensure the database always runs at full capacity with a maximum of 256 connections.
Now, our question about performance can be more specific. Suppose we have multiple sets of database servers with different configurations; what should the fully loaded connection count be for each set to achieve optimal processing capacity?
This requires testing. However, we will ultimately find that this fully loaded connection count is usually related only to the database server’s hardware resources, such as the number of CPU cores, CPU speed, memory size, storage speed, and the bandwidth and latency between storage and host.
Is Database Application Performance Only Related to Hardware Resources?
Of course not. Concurrent performance (P) = Hardware processing capability (H) / Business transaction pressure (T).
As mentioned earlier, the performance metric TPS is for a “determined business transaction pressure,” meaning a determined T value.
When the T value is determined, we can only improve the H value to further enhance the P value. Conversely, there is naturally another optimization approach: reducing the T value. There are various ways to reduce the T value, such as adding necessary indexes, rewriting SQL, using partitioned tables, etc. The optimization plan should be formulated based on where the T value is consumed most, which is another topic.
Conclusion
To answer the two initial questions:
- If concurrent connections increase beyond a certain threshold, PostgreSQL becomes inadequate, and PGBouncer must be used to improve performance. Is this conclusion correct?
If we must create more connections to the database than the hardware processing capacity for certain hardware resources, using PGBouncer can stabilize performance. However, we have no reason to create more connections than the hardware processing capacity. We have various means to control the maximum number of connections the database can open, and various middleware solutions can provide connection pools. From this perspective, PGBouncer does not improve database performance; it merely reduces concurrency conflicts, doing what any connection pool software can do.
- Is it meaningful to attempt various hardware environment combination tests to derive a reference threshold number to guide at what pressure PostgreSQL can cope, and once it exceeds a certain pressure, PGBouncer should be enabled?
It has some significance, but simple stress tests like pgbench are not enough to guide real applications. Concurrent performance (P) = Hardware processing capability (H) / Business transaction pressure (T). Testing in a determined hardware environment means the H value is fixed, so we should focus on T during testing. The T value provided by pgbench is a very simple transaction pressure (only four tables, simple CRUD operations), and the P value tested under this pressure can only be used as a reference. To guide application deployment, typical transaction pressure of the application itself must be abstracted for testing to have guiding significance.
Flashback Features in MogDB
2024-06-15What is Database Flashback
The flashback capability of a database allows users to query the contents of a table at a specific point in the past or quickly restore a table or even the entire database to a time before an erroneous operation. This feature can be extremely useful, and sometimes even a lifesaver.
Database flashback capabilities are generally divided into three levels:
- Row-level Flashback: Also known as flashback query, this typically involves using a SELECT statement to retrieve data from a table as it was at a specific point in time, such as right before a DELETE command was issued.
- Table-level Flashback: Also known as flashback table, this usually involves using specialized DDL statements to recreate a table from the recycle bin. This is often used to recover from a TRUNCATE TABLE or DROP TABLE operation.
- Database-level Flashback: Also known as flashback database, this involves using specialized DDL statements to restore the entire database to a previous point in time. Unlike PITR (Point-In-Time Recovery) which involves restoring from backups, flashback database is faster as it does not require restoring the entire database from backup sets.
In MogDB version 5.0, only flashback query and flashback table have been implemented so far. Flashback database has not yet been implemented (Oracle has supported flashback database since version 10g).
Scenario
Imagine a regrettable scenario (Note: do not run the DELETE SQL command in a production environment).
You have a table that records account names and account balances.
1 | MogDB=# select * from accounts; |
You intended to execute an SQL command to delete account records with a balance of 99 units. Normally, this should delete one record. To demonstrate, let’s use SELECT instead of DELETE.
1 | MogDB=# select * from accounts where amount=99; |
However, the minus sign “-“ and the equals sign “=” are adjacent on the keyboard, and you have fat fingers, so you accidentally pressed the minus sign. As a result, the command you sent to the database looks like this:
1 | delete from accounts where amount-99; |
For demonstration purposes, we’ll still use SELECT instead of DELETE.
1 | MogDB=# select * from accounts where amount-99; |
A terrifying thing happens: all data except the record with a balance exactly equal to 99 is returned. This means that if this were the DELETE command mentioned above, you would have deleted all accounts with a balance not equal to 99.
The good news is that starting from MogDB version 3.0, validation for such dangerous syntax involving the minus sign has been added. Now, executing the same SQL will result in an error.
1 | MogDB=# delete from accounts where amount-99; |
However, in the community editions of openGauss, MySQL, or MariaDB, such dangerous syntax can still be executed normally.
1 | gsql ((openGauss 6.0.0-RC1 build ed7f8e37) compiled at 2024-03-31 12:41:30 commit 0 last mr ) |
No matter what kind of erroneous operation occurs, suppose a data deletion error really happens. In MogDB, you still have the flashback feature available for recovery.
Flashback Feature in MogDB
The flashback feature and its related implementations have undergone some changes since MogDB version 3.0.
Applicable Only to Ustore Storage Engine:
The flashback feature only works for tables using the ustore storage engine. The default astore no longer supports flashback queries. Therefore, you need to set
enable_ustore=on. This parameter is off by default, and changing it requires a database restart to take effect.1
2
3MogDB=# alter system set enable_ustore=on;
NOTICE: please restart the database for the POSTMASTER level parameter to take effect.
ALTER SYSTEM SETSetting
undo_retention_time:This parameter specifies the retention time for old version data in the rollback segment, equivalent to the allowable time span for flashback queries. The default value is 0, meaning any flashback query will encounter a “restore point not found” error. Changing this parameter does not require a database restart.
1
2MogDB=# alter system set undo_retention_time=86400; -- 86400 seconds = 24 hours
ALTER SYSTEM SETEnabling Database Recycle Bin for Truncate or Drop Operations:
To flashback a table from a truncate or drop operation, you need to enable the database recycle bin by setting
enable_recyclebin=on. This parameter is off by default, and changing it does not require a database restart.1
2MogDB=# alter system set enable_recyclebin=on;
ALTER SYSTEM SET
Creating and Populating the Ustore Table
Create a ustore-based accounts table and insert some test data.
1 | MogDB=# create table accounts (name varchar2, amount int) with (storage_type=ustore); |
Simulating an Erroneous Deletion
Now, due to some erroneous operation, you delete all account records with amounts not equal to 99.
1 | MogDB=# delete from accounts where amount<>99; |
Flashback Query
When you realize the mistake, it might be 1 minute or 1 hour later. As long as it is within 24 hours (due to the undo_retention_time setting), you can recover the data.
Check the current timestamp and estimate the timestamp at the time of the erroneous operation. For simplicity, let’s assume you noted the system’s timestamp before issuing the delete command.
1 | MogDB=# select sysdate; |
Issue a flashback query to retrieve the data as it was at the specified timestamp.
1 | MogDB=# select * from accounts timecapsule TIMESTAMP to_timestamp('2024-06-13 18:40:18','YYYY-MM-DD HH24:MI:SS'); |
Recovering Data
You can recover the data by creating a temporary table with the flashback query results and then inserting the data back into the original table.
1 | MogDB=# create table tmp_accounts as select * from accounts timecapsule TIMESTAMP to_timestamp('2024-06-13 18:40:18','YYYY-MM-DD HH24:MI:SS') where amount<>99; |
Alternatively, if no new data has been added to the table after the erroneous operation, you can use the timecapsule table command to flashback the entire table to the specified timestamp.
1 | MogDB=# timecapsule table accounts to TIMESTAMP to_timestamp('2024-06-13 18:40:18','YYYY-MM-DD HH24:MI:SS'); |
Recovering from Truncate or Drop Table
If you accidentally issue a TRUNCATE or DROP command, In this situation, the before commands don’t help because the data has been truncated.
1 | MogDB=# truncate table accounts; |
For TRUNCATE or DROP TABLE operations, use the to before keyword to recover the table from the recycle bin.
1 | MogDB=# timecapsule table accounts to before truncate; |
Similarly, if the table was dropped, you can recover it from the recycle bin using the same to before keyword.
1 | MogDB=# drop table accounts; |
Conclusion
MogDB’s flashback feature is an essential tool for recovering from accidental data deletions, truncations, or drops. By enabling the ustore storage engine, setting an appropriate undo_retention_time, and activating the recycle bin, you can leverage flashback queries and the timecapsule command to restore your data efficiently. These features ensure that you can maintain data integrity and quickly recover from human errors, providing robust data protection and operational resilience.
Exploring Oracle Compatibility in MogDB (Series I) - Data Dictionary
2024-06-06Install PTK
PTK is the optimal tool for installing the MogDB database (an enterprise-grade commercial distribution based on openGauss) or the openGauss database, offering a seamless and smooth installation experience.
To install PTK, simply run the following command:
1 | curl --proto '=https' --tlsv1.2 -sSf https://cdn-mogdb.enmotech.com/ptk/install.sh | sh |
This command will automatically install PTK in the user’s home directory under $HOME/.ptk. This directory will serve as the working directory for PTK, storing cache files, metadata information, cluster configuration information, backup information, and other related files. Additionally, the installation command will add the path $HOME/.ptk/bin to the PATH environment variable in the corresponding shell profile file, enabling the user to use the ptk command directly after logging into the server. In this tutorial, we installed PTK using the root user, although this is not mandatory.
For more detailed PTK installation instructions, please refer to: PTK Installation Guide.
The environment used for this series of articles is CentOS 7.6 for x86-64. MogDB must currently run on a Linux operating system. If you wish to install MogDB on macOS or Windows, you can do so using container deployment. For more information, refer to: Container-based MogDB Installation
To check your CentOS version, you can use the following command:
1 | # cat /etc/centos-release |
MogDB can also run on ARM architecture CPUs. You can list all supported CPU brands using the ptk candidate cpu command:
1 | # ptk candidate cpu |
If PTK notifies you of a new version while running any command, you can upgrade it directly using the ptk self upgrade command.
1 | # ptk ls |
Install MogDB
With PTK, you can easily create multiple MogDB instances on a single server. Each MogDB instance can be assigned to a different operating system user, allowing you to manage multiple database instances with a single PTK installation.
To quickly create a test database without any configuration, you can use the ptk demo command:
1 | # ptk demo |
The ptk demo command accomplishes the following tasks:
- Creates an operating system user named
demo_user_kVP. - Creates a single-instance MogDB database of the latest version (currently 5.0.7).
- Sets the database to listen on port 26000. Before running the
ptk democommand, ensure that port 26000 is not occupied by other applications. - Create an initial database user with the same name as the OS user:
demo_user_kVP. Also, create a monitor user namedmogdb. Both users will have their initial passwords specified in the “Database Detail” section. - Creates two test databases:
oracle_compatibilityin Oracle-compatible mode andpostgres_compatibilityin PostgreSQL-compatible mode. - For the automatically created
oracle_compatibilitydatabase, the following enhancements are also performed:Installs the mogila dataset. For more information about this dataset, refer to: Using Sample Dataset Mogila
Installs the
whaleplugin, which provides extensive Oracle compatibility features. For more information on the Whale plugin, refer to: whaleInstalls the
compat-toolsutility, which supplements thewhaleplugin with additional Oracle compatibility features that are not yet implemented, such as Oracle-compatible data dictionary views. For more information oncompat-tools, refer to: enmotech/compat-toolsNote:
compat-toolsonly work within a single database. This means that if you install compat-tools in theoracle_compatibilitydatabase (as is done automatically by theptk democommand), you will only be able to query the corresponding Oracle-compatible data dictionary views when logged into that database. If you want to use these views in another database, you must install compat-tools in that database as well. For example, if you want to query Oracle-compatible data dictionary views in thepostgresdatabase, you need to downloadcompat-toolsseparately from enmotech/compat-tools then run the following command:1
gsql -h 127.0.0.1 -p 26000 -d postgres -f runMe.sql
Exploring Oracle-Compatible Data Dictionary in MogDB
Switch to the operating system user associated with the demo database. You can log in to the database using the gsql command.
Note: If you want to connect to the database remotely, you should use the mogdb user. The ptk demo command creates two users in the database. One starts with demo_user_, which is the initial user. Due to MogDB’s enhanced security features, the initial user is not allowed to connect remotely. The other user is mogdb, which can be used for remote connections. The initial password for the users is displayed at the end of the ptk demo command output. Additionally, you should modify the pg_hba.conf file to allow remote connections. For more information, refer to: Connecting to a Database Remotely.
1 | # ptk ls |
All these tables come from the Mogila test dataset.
Compat-tools brings a large number of Oracle-compatible data dictionary views (refer to: Oracle-Compatible Views). Here are some simple examples.
1 | -- sysdate function and dual table is supported |
Note: Due to significant differences in the underlying structure between MogDB and Oracle, these Oracle-compatible views may not include all the fields present in the corresponding Oracle database views.
To be continued:
- Exploring Oracle Compatibility in MogDB (Series II) - System Functions
- Exploring Oracle Compatibility in MogDB (Series III) - DBMS Packages
Working Mechanism of synchronous_standby_names in MogDB
2024-06-05In MogDB, the parameter synchronous_standby_names is used to configure synchronous replication settings. When this parameter is set to '*'(default setting), it indicates that any available standby server can be used as a synchronous standby. This configuration allows any currently connected standby to be utilized as a synchronous standby without explicitly specifying the standby’s name.
Working Mechanism
When synchronous_standby_names is set to '*', MogDB’s synchronous replication mechanism selects the synchronous standby through the following steps:
Initial Connection: When the primary server starts or the parameter is changed, the primary server accepts all connected standby servers.
Synchronous Standby Confirmation:
- The primary server sends a synchronization request to all connected standby servers.
- Each standby server, upon receiving the request, confirms it and reports its status back to the primary server.
Selecting the Synchronous Standby:
- The primary server selects the earliest responding standby server(s) as the synchronous standby.
- This selection process is dynamic, meaning that if new standbys connect or current synchronous standbys disconnect, the primary server will reselect the synchronous standby.
Priority and Behavior
- No Priority Order: Since
'*'denotes any standby, all standbys have the same priority. The primary server simply selects the earliest responding standby as the synchronous standby. - Dynamic Adjustment: If a synchronous standby disconnects, the primary server automatically selects the next responding standby as the new synchronous standby, ensuring the continuity and reliability of synchronous replication.
- Concurrent Management: If multiple standbys connect simultaneously, the primary server can handle these concurrent connections and select the synchronous standby based on the confirmation of synchronization requests.
Configuration Example and Usage
Suppose we have one primary server and three standby servers (standby1, standby2, and standby3). In the configuration file postgresql.conf, set synchronous_standby_names to '*':
1 | synchronous_standby_names = '*' |
Scenario Analysis
Selection at Startup:
- When the primary server starts, all connected standby servers send heartbeat signals and wait for the primary server’s synchronization request.
- The primary server selects the earliest responding standby as the synchronous standby.
Runtime Changes:
- If the current synchronous standby
standby1disconnects, the primary server automatically selects the next responding standbystandby2as the new synchronous standby. - If a new standby
standby3connects to the primary server and there is no current synchronous standby, the primary server selectsstandby3as the synchronous standby.
- If the current synchronous standby
Dynamic Adjustment
If we start the primary server and three standby servers, setting synchronous_standby_names = '*', the following state transitions are possible:
- Initial State: All standbys (
standby1,standby2, andstandby3) connect, and the primary server selects the earliest responding standbystandby1as the synchronous standby. standby1Disconnects: The primary server automatically selects the next responding standbystandby2as the new synchronous standby.- New Standby Connection: A new standby
standby4connects; the primary server will not change the current synchronous standby unlessstandby2disconnects.
Summary
When synchronous_standby_names is set to '*', MogDB dynamically selects any currently available standby as the synchronous standby. This provides a flexible and highly available synchronous replication mechanism without requiring administrators to manually specify the standby names. The selection process is based on standby response times and automatically adjusts during runtime to ensure the continuity and reliability of synchronous replication.
MTK: The Ultimate Tool for Seamlessly Migrating Oracle Databases to MogDB
2024-06-03Get the latest version MTK.
1 | wget https://cdn-mogdb.enmotech.com/mtk/v2.6.3/mtk_2.6.3_linux_amd64.tar.gz |
Generate MTK trial license online
The trial license is valid for 1 month, and each email address can generate only one license. However, email addresses with the “enmotech.com” domain can generate licenses repeatedly. If clients wish to extend their trial of MTK beyond the initial month, they should contact Enmotech’s sales or pre-sales team to request an additional 1-month license.
1 | [kamus@altlinux10 mtk_2.6.3_linux_amd64]$ ./mtk license gen |
Upon receiving the email, upload the attached license.json file to the MTK directory. Then, use the command mtk -v to verify the license validation.
1 | [kamus@altlinux10 mtk_2.6.3_linux_amd64]$ ./mtk -v |
Install Oracle instant client
MTK requires the Oracle Instant Client to migrate Oracle objects to MogDB. In this tutorial, we will download the Oracle Instant Client for Linux x86-64 Basic Package. After downloading, unzip the file and set the LD_LIBRARY_PATH parameter as follows:
1 | export LD_LIBRARY_PATH=/home/kamus/instantclient_21_7:$LD_LIBRARY_PATH |
In this tutorial, we will migrate a sample schema “customer_orders” to MogDB. The scripts for Oracle can be downloaded from the db-sample-schemas repository on GitHub.
Initialize migration project
1 | ./mtk init-project -s oracle -t mogdb -n ora2mogdb |
Modify MTK configuration file
Modify the example MTK configuration file stored in the project_name_dir/config directory. Refer to the MTK documentation for detailed information on each parameter. The essential configuration sections for MTK are source, target, and object.
sourcesection: This defines the connection to the source database. MTK needs to query the Oracle database dictionary to retrieve DDL. Therefore, it is typically recommended to use a DBA user, with the default system user being sufficient.targetsection: This defines the connection to the target database.objectsection: To migrate all objects within a schema, simply specify the schema name in theschemassection.
The mtk.json configuration file should look like this:
1 | { |
For this tutorial, we plan to migrate all objects in the “CO” schema from the Oracle database to the same user in MogDB. For testing purposes, we will not create a new database in MogDB. Instead, we will create a new user “co” in the default database, postgres.
Run the following command to create the user:
1 | [omm@altlinux10 ~]$ gsql -d postgres -p 26000 -r |
Start migration
Now, we can start migration.
1 | ./mtk -c ora2mogdb/config/mtk.json |
Check migration report
The migration result report will be generated in the project report directory, available in both plain text and HTML formats. For simplicity, I have included the text format result in this tutorial.
1 | ----------------------- |
We can see that all tables and table data have been successfully migrated to MogDB without any errors. However, there is one failed constraint and two failed views.
The failed constraint is a JSON check constraint, which is not supported by MogDB.

The failed views are due to the grouping_id function and the json_table function, which are not yet implemented in MogDB ().
| SQL | ERROR |
|---|---|
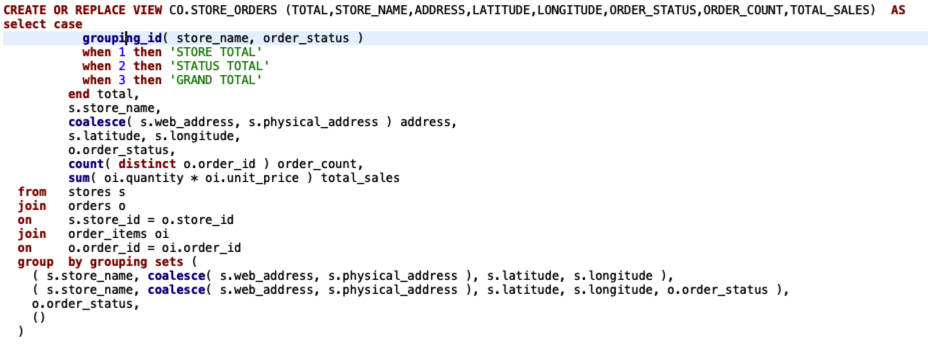 |
pq: function grouping_id(character varying, character varying) does not exist |
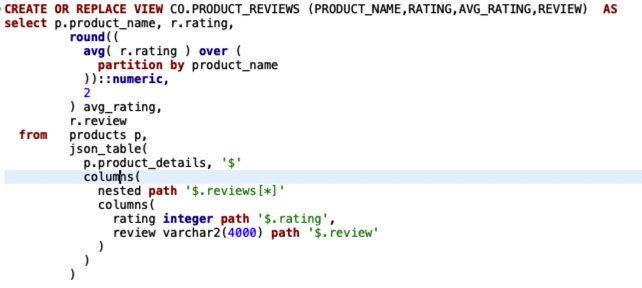 |
pq: syntax error at or near “columns” |
Check migration result
Run the sample queries to ensure that all the data has been migrated to MogDB without any errors.
1 | /* 5 products with the highest revenue |
1 | MogDB=> select p.product_name, |
Conclusion
Migrating tables, table data, and indexes from Oracle to MogDB typically proceeds without issues. However, for views, procedures, functions, and packages, some modifications to the source code may be necessary. With the ongoing development of Oracle compatibility in MogDB, we believe that the need for such modifications will decrease over time, making the migration process from Oracle to MogDB even smoother.
Ensuring Data Integrity: How Major Databases Handle Partial Writes and Atomic Operations
2024-05-30In the world of databases, ensuring atomicity in write operations is crucial. This post explores the importance of atomic writes and how various databases handle potential issues like partial writes.
Understanding Partial Writes
In the I/O write chain, the size of atomic operations can vary. An operation at a higher level may be split into multiple operations at a lower level, leading to scenarios where some operations succeed while others fail. This phenomenon is known as a partial write.
- Legacy Disk Drives: Default sector size is 512 bytes.
- Modern Disk Drives: Advanced format sector size is 4k.
- Filesystem Page Size: For example, ext4 has a default page size of 4k.
- Database Page Sizes:
- Oracle: 8K
- MySQL: 16K
- PostgreSQL: 8K
- openGauss: 8K
The Reality of Partial Writes
While theoretically, databases must handle partial writes, in practice, such events are quite rare. The critical aspect is not just preventing partial writes but ensuring robust mechanisms for data integrity checks (checksums) and recovery when issues do arise.
How Oracle Handles Partial Writes
Oracle’s approach to partial writes is pragmatic:
- Automatic Repair: If a fractured block is detected, Oracle tries to repair it using the corresponding block from Active Data Guard (ADG) or the flashback log.
- Error Reporting: If automatic repair fails, an ORA-01578 error is logged, prompting the DBA to perform a media recovery.
- Block-Level Recovery: Oracle supports block-level recovery, making the process less cumbersome and time-consuming.
Oracle’s backup sets are designed to handle partial writes:
- Using OS Commands: When backing up data files using OS commands, Oracle requires the tablespace to be in backup mode. Any changes to data blocks are logged in the redo log, ensuring a clean block can be restored during recovery.
- Using RMAN: RMAN handles partial writes by ensuring that each backup block is clean, eliminating the need to worry about fractured blocks.
- Block Checking: Oracle provides mechanisms like DB_BLOCK_CHECKING for comprehensive checksums.
How MySQL Handles Partial Writes
MySQL employs a double write buffer to safeguard against partial writes.
- Double Write Buffer: Despite its name, the double write buffer is not stored in memory; instead, it consists of persistent files on disk. The mechanism works as follows: before writing a data block to its final location on disk, MySQL first writes it to the double write buffer.
- Data Integrity: This approach ensures that there is always a clean copy of the block available—either in the double write buffer or in the data files—allowing for safe redo operations.
However, this method is not without its challenges. One of the primary concerns is its efficiency, as it effectively doubles the I/O workload for redo logging. This has sparked ongoing discussions about the trade-offs and effectiveness of using a double write buffer to address partial writes.
How PostgreSQL Handles Partial Writes
PostgreSQL employs full page writes to manage partial writes effectively:
- Full Page Writes: When a data block is updated for the first time after a checkpoint, the entire block is written to the WAL (Write-Ahead Logging) log. This is akin to the database always being in “Backup status,” similar to issuing the
alter tablespace x begin backupcommand in an Oracle database. - Data Integrity: This mechanism ensures that even if a partial write occurs, the database remains consistent because the original page can be used for redo operations.
There has been community discussion about adopting a double write buffer mechanism, but it remains an area of interest rather than active development. For more details, you can check out these discussions:
- Discussion on Double Write Buffer Mechanism (Post 1)
- Discussion on Double Write Buffer Mechanism (Post 2)
How MogDB Handles Partial Writes
MogDB (the enterprise edition of openGauss) combines strategies from MySQL and PostgreSQL:
- Double Write Buffer: Similar to MySQL, MogDB uses a double write buffer by setting
enable_double_write=on. - Full Page Writes: MogDB retains PostgreSQL’s full page write mechanism by setting
full_page_writes=on.
Depending on the configuration of incremental checkpoints (enable_incremental_checkpoint):
- Incremental Checkpoints Off:
- With
full_page_writes=on, full page writes are used. - With
full_page_writes=off, partial writes are not a concern.
- With
- Incremental Checkpoints On:
- With
enable_double_write=on, double writes are used. - With
enable_double_write=off, the behavior depends on full_page_writes settings.
- With
Conclusion
Ensuring atomic writes in databases is essential for data integrity and consistency. While partial writes are rare, robust mechanisms for detection and recovery are vital. Oracle, MySQL, PostgreSQL, and MogDB/openGauss each have unique approaches to handling these scenarios, ensuring that data remains reliable and recoverable.
How to build blog site by using Hexo in Windows WSL and deploy to GitHub Pages
2024-05-27Why use WSL
Using Windows Subsystem for Linux (WSL) instead of relying solely on Windows can offer several advantages, particularly for developers and IT professionals. WSL allows users to run a GNU/Linux environment directly on Windows, without the overhead of a traditional virtual machine or dual-boot setup. This enables seamless access to a wide range of Linux tools and utilities, which are often preferred for development tasks, scripting, and system administration. Additionally, WSL provides a more consistent and familiar environment for those accustomed to Unix-based systems, facilitating smoother workflows and integration with cloud-based services. By leveraging WSL, professionals can enjoy the best of both worlds: the robust software ecosystem of Windows and the powerful command-line capabilities of Linux.
Why use Hexo
Hexo offers several advantages over WordPress, particularly for developers and tech-savvy users. As a static site generator, Hexo provides faster load times and improved security since it does not rely on a database or server-side processing, which are common vulnerabilities in WordPress. Additionally, Hexo allows for greater customization through its use of Markdown and extensive plugin ecosystem, enabling users to tailor their sites to specific needs without the overhead of a complex content management system. Furthermore, Hexo’s deployment process is streamlined, often integrating seamlessly with version control systems like Git, making it an excellent choice for those who prioritize efficiency and performance in their web development projects.
Why use Github Pages
Using GitHub Pages instead of a traditional hosting server offers several distinct advantages. Firstly, GitHub Pages provides a seamless integration with GitHub repositories, enabling automatic deployment of websites directly from your codebase. This integration ensures that updates and changes to your site are effortlessly managed through version control, promoting a streamlined workflow. Additionally, GitHub Pages is cost-effective, offering free hosting with custom domain support, which can significantly reduce overhead costs for personal projects or small businesses. The platform also boasts robust security features, leveraging GitHub’s infrastructure to protect your site from common vulnerabilities. Furthermore, the simplicity and ease of use make GitHub Pages an attractive option for developers who want to focus on writing code rather than managing server configurations and maintenance. Overall, GitHub Pages combines efficiency, cost savings, and security, making it an excellent choice for hosting static websites and project documentation.
GO!
Assume already has a WSL environment running
If not, refer to “How to install Linux on Windows with WSL“.
To say we are running WSL distro - Ubuntu 22.04
1 | $ cat /etc/os-release |
Install Node.js
Since Hexo is written by Node.js, nodejs must be installed.
1 | sudo apt update |
Install GIT
Since Hexo uses Git to publish pages on GitHub, Git must be installed.
1 | sudo apt install git |
Install Hexo
1 | sudo npm install -g hexo-cli |
Init Hexo project
Our goal is to deploy the static HTML file generated by Hexo to GitHub Pages. To achieve this, we need to create a repository named “[username].github.io” on GitHub. Therefore, we will initialize this directory directly using Hexo. Note: Be sure to replace [username] with your actual GitHub username.
1 | hexo init kamusis.github.io |
Create Github pages
Creating GitHub Pages is very simple, reference: https://pages.github.com/
Connecting to Github with SSH
Reference: https://docs.github.com/en/authentication/connecting-to-github-with-ssh
Basically, generate a key using the ssh-keygen command and upload the public key to the GitHub.
Once the SSH connection is established, use the following command to verify it:
1 | $ ssh -T git@github.com |
Set URL for your new blog
1 | $ vi _config.yml |
Set Git information to let hexo can push contents into Github Pages
1 | $ npm install hexo-deployer-git --save |
Generate the site and push to Github pages
1 | $ hexo clean |
Assuming everything has been set up correctly, you can now view a hello-world article on a website by navigating to https://[username].github.io.
Write your articles and publish
1 | hexo new "My first post" |
A markdown file will automatically be created and placed in the source/_posts directory. It can then be edited and saved using your preferred text or markdown editor.
Of course, you can also clean up the initial hello-world article.
1 | rm source/_posts/hello-world.md |
Publish the articles.
1 | $ hexo clean |
Reference:
https://hexo.io/docs/github-pages#One-command-deployment
https://gist.github.com/btfak/18938572f5df000ebe06fbd1872e4e39
How to Find the Corresponding Session in MogDB/openGauss from OS Thread ID
2024-05-27Diagnostic Needs
When the MogDB database consumes a significant amount of system resources, such as nearly 100% CPU usage, how can we determine which session(s) in the database are using these resources?
In Oracle databases, diagnosing such issues typically involves associating v$session, v$process, and the OS process ID found using the top or ps commands. However, MogDB uses a thread model, and only one process ID is visible at the OS level. So, how do we pinpoint the problem?
Since MogDB uses a thread model, unlike PostgreSQL’s process model, checking network port access with the lsof command at the OS level will show multiple user sessions connected, but only the process ID will be displayed in the PID column, not the thread.
1 | lsof -i 4 -a -p `pgrep -u omm3 mogdb` |
How to Get Thread ID
You can use htop. After opening htop, press F5 to display the process tree. The first PID is the process ID, and each line under the tree structure shows the corresponding thread ID for that process.
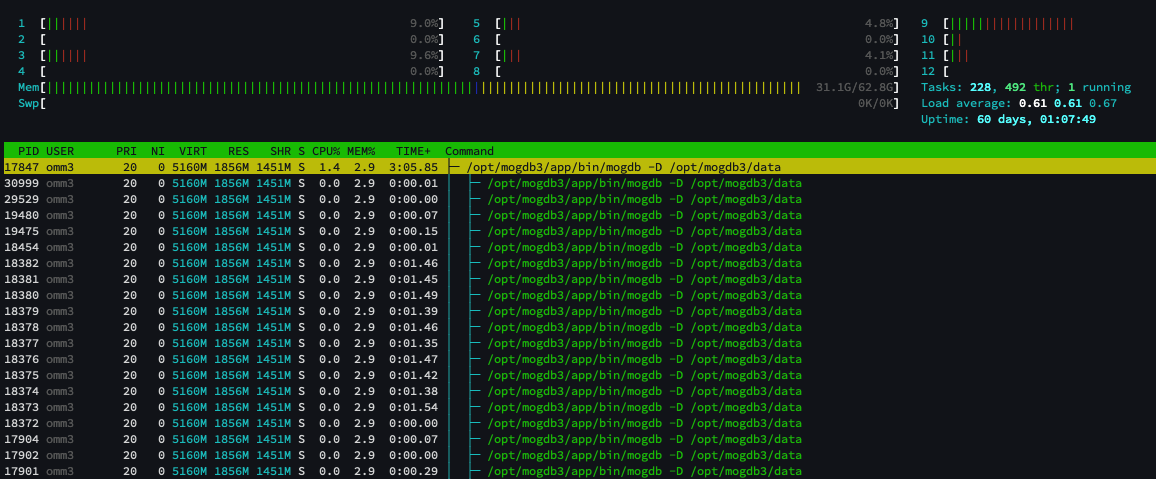
You can also use the ps command. The -L parameter displays threads, and the -o parameter specifies the columns of interest.
1 | ps -Lp `pgrep -u omm3 mogdb` -o %cpu,tid,pid,ppid,cmd,comm |
The rows in the comm column that display as “worker” are backend processes of user sessions in the database. Typically, user sessions that consume high CPU can be filtered to show only user sessions using the grep command.
How to Map OS Thread ID to Database Session
Suppose on this server, the thread with ID 18372 is consuming a lot of CPU. In MogDB, you can query the pg_os_threads view to find the session ID corresponding to this thread.
1 | MogDB=# select * from pg_os_threads where lwpid=18372; |
The pg_os_threads view records the relationship between lightweight thread IDs and session IDs. The lwpid column is the OS thread ID, and the pid column is the database session ID. For detailed information, refer to the MogDB documentation on PG_OS_THREADS.
If you have monadmin privileges, you can also query the os_threads view in the dbe_perf schema, which provides the same information.
After finding the database session ID, you can perform various actions, such as querying the dbe_perf.session_stat_activity view to get the application name, client IP address, and the SQL query being executed by that session.
1 | MogDB=# select application_name, client_addr, query from dbe_perf.session_stat_activity where pid=140545137571584; |
You can also query the dbe_perf.thread_wait_status view to get the current wait event of the session. Note that this view contains the lwtid field, which directly corresponds to the thread ID.
1 | MogDB=# select lwtid, wait_status, wait_event from dbe_perf.thread_wait_status where sessionid=140545137571584; |
MogDB ASH: Unveiling the Active Session History for Powerful Database Performance Tuning
2024-05-27What is ASH?
ASH, or Active Session History, is a feature in Oracle databases that records information about active sessions at regular intervals in both the database memory and persistent system tables. Data in memory is cleared after a database restart, but data in the persistent system tables is retained for a longer period. ASH is extremely useful for diagnosing issues when the database encounters problems or performance issues by allowing retrospective analysis to identify the root cause.
In MogDB, a similar ASH capability is implemented.
ASH Capability in MogDB
The ASH capability in MogDB is divided into two parts: the open-source community version (openGauss) and the enhanced enterprise version.
1. openGauss Community Version:
MogDB inherits the ASH capability from openGauss. The database provides two main views: dbe_perf.LOCAL_ACTIVE_SESSION and GS_ASP. The LOCAL_ACTIVE_SESSION view is an in-memory table, while GS_ASP is a persistent table. These views contain sampling information about current active sessions.
Key parameters affecting ASH functionality:
- enable_asp: Set to
onoroffto enable or disable ASH functionality. Default ison. - asp_sample_interval: Specifies the interval between each sample. Default is 1 second. To reduce sampling pressure, this can be set to a longer interval, up to a maximum of 10 seconds.
- asp_sample_num: Specifies the total number of samples retained in the
LOCAL_ACTIVE_SESSIONin-memory table. Exceeding this number triggers a flush of in-memory samples to theGS_ASPsystem table and clears the in-memory table. Default is 100,000 samples. - asp_flush_rate: Determines which in-memory samples are flushed to the
GS_ASPtable. Samples withsampleid % asp_flush_rate == 0are marked asneed_flush_sample=trueand are persisted. Default is 10, meaning 1/10 of samples are persisted. - asp_retention_days: Specifies the retention period for data in the
GS_ASPtable. Default is 2 days, with a maximum of 7 days.
2. MogDB Enterprise Version:
The enterprise version enhances ASH capability, termed “SQL Execution State Observation,” by adding sampling of SQL execution operators. The plan_node_id field is added to views to record the execution operator during each sample, allowing identification of which step in the execution plan is causing performance issues.
Key parameters affecting enterprise ASH functionality:
- resource_track_level: Set to
operatorto enable operator sampling capability. Default isquery, which records only SQL-level sampling.
LOCAL_ACTIVE_SESSION View
This view records extensive information, including session ID, wait events, and SQL query ID (which can be linked to dbe_perf.statement_history or dbe_perf.statement_complex_runtime to retrieve SQL text and execution plans).
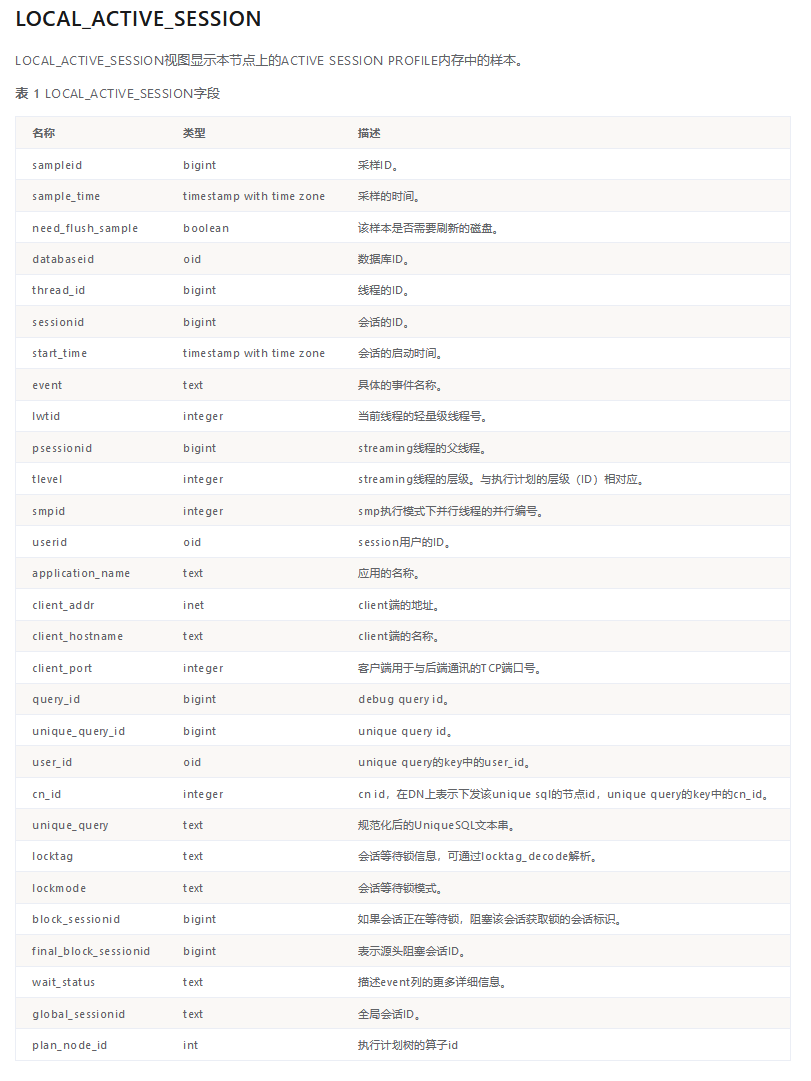
Note: The plan_node_id field exists only in the enterprise version.
Recording SQL Execution Plans
Querying the execution plans of past or currently executing SQL is a common requirement in database maintenance. In MogDB, the following views record SQL execution plans:
- dbe_perf.STATEMENT_HISTORY: Records information about completed SQL, including execution plans (
query_planfield). - dbe_perf.STATEMENT_COMPLEX_RUNTIME: Records information about currently executing SQL, including execution plans (
query_planfield).
Parameters affecting recording of SQL execution plans:
- enable_resource_track: Enables or disables resource tracking. Default is
on. If set tooff, no user SQL execution information, including execution plans, is tracked. - resource_track_cost: Sets the minimum execution cost for SQL statements to be tracked. Only SQL with a cost above this value will have its execution plan recorded.
Comprehensive Query Example
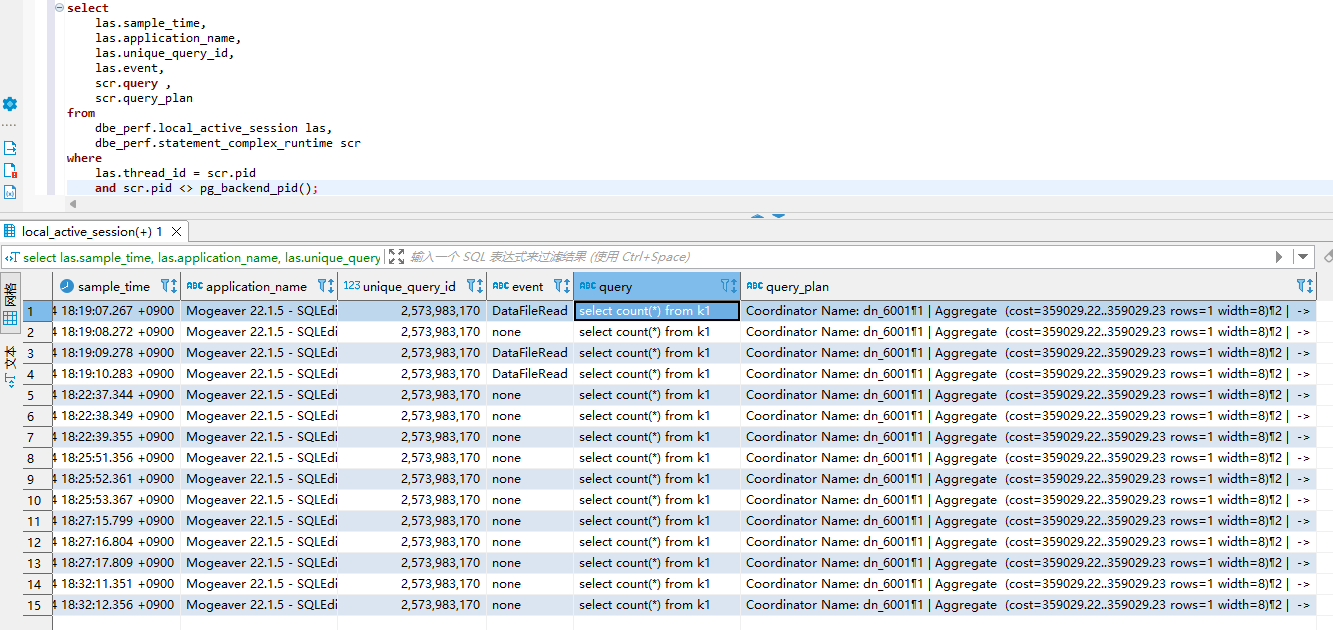
The following query retrieves all information about ongoing SQL executions, including historical samples:
1 | SELECT las.sample_time, las.application_name, las.unique_query_id, las.event, scr.query, scr.query_plan |
Example output shows a frequently executed full table scan query, including SQL text, execution plan, and client information, providing valuable data for performance diagnosis.
How to move WSL distro in Windows 11 to another drive
2024-05-27Introduction:
In the world of development and system administration, Windows Subsystem for Linux (WSL) has become a valuable tool. It allows users to run a Linux distribution alongside their Windows environment, opening up a world of possibilities for developers and administrators. In this article, we’ll guide you through the process of migrating a WSL instance, using a real-world example, step by step.
Prerequisites:
Before we begin, ensure that you have the following prerequisites in place:
- Windows 10 or later with WSL installed.
- An existing WSL instance (in our case, Ubuntu).
- Sufficient storage space for the migration.
Step 1: Create a Target Directory
To start the migration process, we need a target directory to store the migrated WSL instance. In PowerShell, use the ‘mkdir’ command to create this directory. In our example, we create a directory named ‘D:\WSL\Ubuntu’:
1 | mkdir -p D:\WSL\Ubuntu |
Step 2: List All Running WSL Instances
Before we proceed further, let’s list all the running WSL instances. The following command will display a list of all WSL instances, including their state and version:
1 | wsl -l --all -v |
Step 3: Export the Source WSL Instance
Now, let’s export the source WSL instance (in our case, ‘Ubuntu’) into a tar file. This step automatically shuts down the WSL instance and restarts it after the export:
1 | wsl --export Ubuntu D:\WSL\Ubuntu.tar |
Step 4: Unregister the Source WSL Instance
Once the export is complete, we need to unregister the source WSL instance to avoid conflicts. Use the following command:
1 | wsl --unregister Ubuntu |
Step 5: Confirm Unregistration
To confirm that the source WSL instance has been successfully unregistered, run the following command:
1 | wsl -l --all -v |
Step 6: Import into the Target Directory
Now it’s time to import the previously exported WSL instance into the target directory. In this step, we specify the target directory and version (in our case, version 2):
1 | wsl --import Ubuntu D:\WSL\Ubuntu D:\WSL\Ubuntu.tar --version 2 |
Step 7: Verify the Migration
To ensure that the migration was successful, list all WSL instances once again:
1 | wsl -l --all -v |
Step 8: Access the Migrated WSL Instance
Now, you can access the migrated WSL instance by using the following command:
1 | wsl -d Ubuntu |
Conclusion:
Migrating WSL instances is a powerful way to manage and organize your development environments. By following these steps, you can seamlessly move your WSL instances to different directories or machines, ensuring flexibility and efficiency in your development workflow. Keep in mind that WSL provides a bridge between Windows and Linux, allowing you to enjoy the best of both worlds.
Check the all steps screenshot as below.
1 | # create target directory |